APIサーバーの観点からイベント駆動アーキテクチャ(Event Driven Architecture)を学ぼう
たまに開発をしていると、APIの応答が遅い時があります。このような場合、APIの応答を速くするためにコードを最適化したり、キャッシュを適用するなどの方法を使用することができます。
もちろんこれらの方法が可能であれば良い方法であり、最善ですが、時にはどうしても時間がかかる作業があります。
AWSを例にしてみましょう。特定のAPIがあり、EC2マシンを立ち上げるAPIがあると仮定します。この時、EC2マシンを立ち上げるAPIはかなり時間がかかる作業です。しかし、コードの最適化だけでこの時間を短縮できるでしょうか?
コンピュータをオン・オフする作業はどんなに最適化しても、かなり時間がかかるでしょう。(筆者のコンピュータも起動するのに30秒は軽くかかります)
これを同期APIで処理するならば、次のように構成できるでしょう。
Go言語を通じて一度見てみましょう。
package main
import "net/http"
func StartEc2Handler(w http.ResponseWriter, r *http.Request) {
// ...
// EC2マシンを立ち上げるコード
// ...
w.Write([]byte(`{"result": "success"}`)) // JSON形式で応答
}単純に層間の区分なしにコードが書かれています。実際のコードではservice、repositoryなどさまざまな階層があるでしょう。
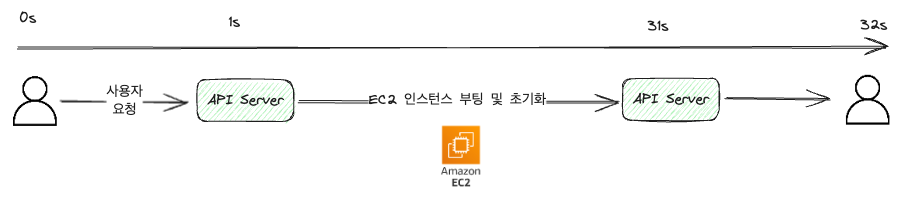
上の図の例では便宜上、極端にユーザー -> サーバ間の通信に1秒かかると仮定しています。(実際にはミリ秒単位でずっと短いです。)
図で見られるように、APIリクエストを受けてEC2マシンを立ち上げる作業を処理し、その結果を返す方式です。
同期方式ではリクエストを受けたとき、そのリクエストを処理するまで応答しないため、ページを離れたり、リフレッシュしたりする作業を行うと作業が途中で中断されます。
ユーザーの立場では次のようなローディング画面を32秒間見なければならないことになります。
これほど恐ろしいことはないでしょう。
途中で切れるのを防ぐために次のように警告が出るように処理する場合もあります。しかし、ユーザーが確認を押すことを防ぐことはできません。
筆者の場合、B2Bサービスで商品1個を3つの外部サービスにアップロードするのにかかる時間が1個あたり10秒程度でした。一般的に100~200個単位でアップロードするため、ユーザーが10分以上待つのは非常に不便なことです。
コンピュータを10分間使わないでください。-> 耐えられるでしょうか?
解決1. APIを非同期にする
イベント駆動で処理する前に、非同期APIで作業を処理することができます。
Goが同時処理が簡単なほうなので、Goを例にとると次のようになります。
package main
import "net/http"
func StartEc2Handler(w http.ResponseWriter, r *http.Request) {
// ...
go func() {
// EC2マシンを立ち上げるコード
// 成功/失敗に関するユーザー通知を作成するコード
}()
// ...
w.WriteHeader(http.StatusAccepted) // 202 Accepted: リクエストが受信され、作業が開始されたことを示す
}上記のコードはEC2マシンを立ち上げるコードをゴルーチンで処理し、リクエストが受信され、作業が開始されたことを示すために202 Acceptedを返すコードです。
これだけでも次のようにリクエスト -> 応答でつながる時間を大幅に短縮できます。
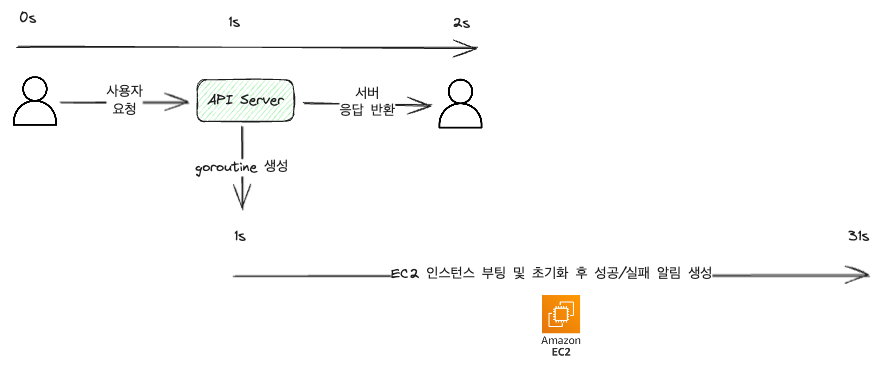
上の図だけでもユーザーのリクエストは2秒ほどしか取っていなくて、非常に速く応答を受けることができますが、通知を生成するコードが追加されました。
なぜなら、202は単に受信されたことを知らせるだけで実際に作業が完了したかどうかは保証されないためです。
したがって、このように成功/失敗に関係なく応答する場合には通知やステータスコードなどを追加してクライアントに作業の成功/失敗を知らせることができるようにする必要があります。
もちろん、通知処理をしなくてもコードとしては問題ありません。しかし、開発者ならば、ユーザーが通知などを通じて作業の成功/失敗を知らないということがユーザー体験を大きく損ない、早急に通知を追加することを考慮する必要があります。
倒した…かな?
そうではありません。世の中には多くの制約事項があり、多くの問題があります。
次のようなコードを増やしていくといくつかの問題に直面することになりますが、筆者が直面した問題は次の3つのことでした。
- 一般に、非同期タスクは負荷が大きいタスクです(そうでなければ同期で処理するのが簡単であり問題ありませんでした)。そのため、該当APIへのトラフィックが増えるとサーバーがすぐにダウンする可能性があります。
- 配布、天災地変などの理由で作業が中断される場合、復旧が難しく、ユーザーには通知が送られません。
- 自社サービスではない外部サービスAPIの場合、一般的にRate Limitが存在し、リクエストが集中すると、429 Too Many Requestsで外部サービスで正常に作業が処理されない可能性があります。
解決2. イベント駆動アーキテクチャ(Event Driven Architecture)で処理する
イベント駆動アーキテクチャは、その名の通りイベントに基づいて作業を処理するアーキテクチャを意味します。
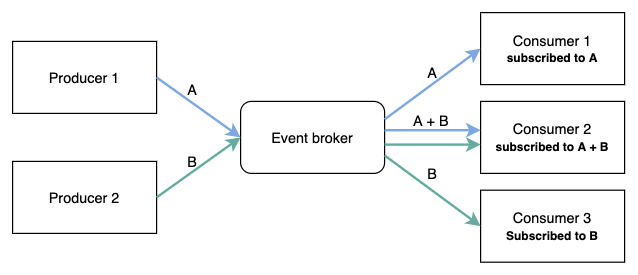
途中にEvent Brokerが存在し、Producerがイベントを発行し、Consumerがイベントを購読する方式で作業を処理します。
Event Brokerは代表的にはKafka、RabbitMQ、AWS SNSなどがあり、ProducerとConsumerはこれを通してイベントをやり取りします。
実質的に作業(EC2マシンを立ち上げるなど)を処理するのはConsumerが担当し、Producerはリクエストを受けるとイベントを発行し、該当APIは202 Acceptedを返します。
コードを見てみましょう。
以下の例ではRabbitMQを使用し、イベントを発行し、これを購読する方式で作業を処理しています。
package main
import (
"net/http"
amqp "github.com/rabbitmq/amqp091-go"
)
func PublishStartEc2EventHandler(w http.ResponseWriter, r *http.Request) {
// rabbitmq接続とchannelを取得
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
w.Write([]byte(`{"result": "rabbitmq connection error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
ch, err := conn.Channel()
if err != nil {
w.Write([]byte(`{"result": "rabbitmq channel error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
// イベント発行
event, err := json.Marshal(Event{
Code: "START_EC2",
RequestID: "some_uuid",
Body: "some_body",
})
if err != nil {
w.Write([]byte(`{"result": "json marshal error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
if err = ch.PublishWithContext(
r.Context(),
"",
"aws-event-queue",
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: event,
}); err != nil {
w.Write([]byte(`{"result": "rabbitmq publish error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
w.WriteHeader(http.StatusAccepted)
}コードは少し長いです。実際に重要なのはコードではなく、このAPIの役割です。
このAPIでは、RabbitMQ接続 -> イベントオブジェクトの作成 -> JSONシリアライズ -> イベントオブジェクトをBodyに入れてイベントを発行の順で作業を処理します。
実際にはキューとの接続自体も一般的にはアプリケーション起動時に接続を共有して使用するため、必要ではない場合が大多数ですが、該当ケースでは突然
conn.Channel()が登場すると何かと思われることを想定して、理解を助けるためにコードに含めました。
Consumerコードは機能によって非常に長くなるため、次の図で省略します。
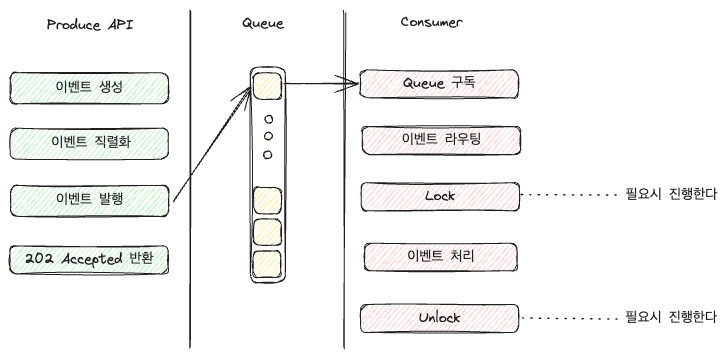
ルーティングの場合、構成に応じて各イベント専用のキューを作成してキューで直接処理することもでき、上図のようにアプリケーションでイベントを受け取りルーティングすることもできます。
ただし、上図のようにConsumerの役割が増え、イベントが増えるほど条件分岐に対する負担が増すことがあります。
規模がもう少し大きくなると(正確には管理が難しくなると)、イベント分岐を処理する別のレイヤを設けたり、Consumerを指定するLBのようなものを設けることもあるかもしれません。
なぜロックを掛けるのか?
イベント駆動アーキテクチャでは、Consume時に選択的にロックを掛けることができます。
ロックはRedisLock、DB Lockなど特定のリソースに対する同時制御を行うための方法です。
ロックは一般的に、ロックを掛けておくと他のConsumerが特定のイベント、または特定のキューを処理できないようにすることができます。そして作業が終了したらロックを解除し、他のConsumerが該当イベントを処理できるようにします。
筆者の場合、次のような理由で主にロックを掛けました。
- マルチコンテナ環境では必然的にConsumerが複数存在します。ロックを別途掛けない場合、他のコンテナが該当キューで作業を行っていることを知ることができない可能性があるため、コンテナの数だけ同時に消費する場合があります。筆者の場合、このように同時に処理されるイベントの量を制限するためにロックを掛けました。
- Consumerが複数ある場合、同一のイベントを処理する場合があるため、これを防ぐためにロックを掛けました。
- 外部サービスの場合、ほとんどの負荷を防ぐために一度に処理できるリクエスト数が決まっています。筆者の場合、Rate Limitが1秒で2個程度と非常に制限されていたため、一度に処理される外部サービスAPIが1つであることを保証するためにロックを掛けました。
Event Chain
イベント駆動アーキテクチャの長所は、イベントチェーンを通じて複数のイベントをつなぐことができるという点です。
例として、EC2ハンドラーの場合、2つの作業がありました。
- EC2マシンを立ち上げる作業
- 立ち上げたEC2マシンに対する通知を作成する作業
これをイベントチェーンにすると次のようになります。
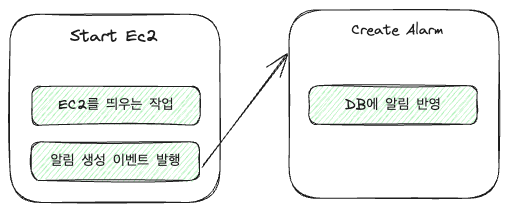
コードで見るとさらに簡単で、非常に単純に構成すると次のようになります。
func StartEc2Event(args any) {
// EC2マシンを立ち上げる作業
// ... Some code
// CreateAlarmイベントを発行
ch.PublishWithContext(
r.Context(),
"",
"aws-event-queue",
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: event, // 大体該当作業が成功したという内容
})
}
func CreateAlarm(args any) {
// 通知作成
}コンシューマーの関数ですが、StartEc2Event関数を見るとイベントを消費して新しくイベントを発行します。これにより、順序がある次の作業をイベントベースで容易に実現できるようになります。
イベントが標準化されていればいるほど、再利用性が高まります。例に示されたCreateAlarmの場合、単に該当ケースだけでなく、このような非同期作業ならばどんなイベントでもそのまま使用可能でしょう。
生産性の点では、一度実装したイベントを再実装する必要がないという点で非常に大きな利点として受け止められるでしょう。
短所
このように図では非常に簡単に見えますが、コードで見ると状況によって非常に複雑になることがあります。
イベントチェーンが深くなればなるほど、その流れを追うのが非常に困難であり、デバッグ時にも各イベント間の関係を把握するのが難しい場合があります。
そのため、イベントは非常に良く文書化されている必要があります。
終わりに
イベント駆動アーキテクチャは、うまく使えば非常に強力なアーキテクチャのひとつです。ConsumeされるAPIの数を調整することで、サーバーの負荷を減らすことができ、イベントチェーンを通じて再利用性を高めることができます。
ユーザーの立場でも、リクエスト -> 応答に対する待機時間を減らしつつ、他の作業を行うことができる便利な技術です。ただし、モニタリングなどの部分でもトランザクションで一つにまとめるために別途の設定が必要であり、イベントオブジェクトを誤って作成すると、単に同期APIで処理するよりも複雑度が高くなることがあります。
そのため、筆者はイベント駆動アーキテクチャを使用する際にはチームメンバーと十分な議論を行い、コンベンションを事前に確立し、これをしっかりと守り、維持することが重要だと考えています。