GolangでPlaywrightを利用してクロールしてみよう
データを収集する方法はいくつかありますが、一番一般的な方法がクロール(Crawling)という技法を利用することです。
クロールとは直訳すると「這い回る」という意味です。ウェブクロールはウェブを這い回って情報を収集することだと考えればよいでしょう。
ツール
Pythonで特に多く利用される理由は、Python言語の簡潔さもありますが、クロールに特化したライブラリが多いからです。よく知られたツールとしては、BeautifulSoup、Selenium、Scrapyなどがあります。
最近はPlaywrightというツールが登場していますが、一般的にはクロールよりもテスト自動化に多く使用されますが、クロールにも利用することができます。
単純にパーサーの役割を果たすBeautifulSoupとは異なり、Playwrightは実際のブラウザを基にブラウザ関連のアクションを制御できるため、JavaScriptを実行したり、SPA(Single Page Application)をクロールする際に有用に使用することができます。
このツールはNode.js、Python、Goなど、様々な言語をサポートしていますが、今回はGoでPlaywrightを使用してみようと考えています。
Playwrightのインストール
GoでPlaywrightを利用するためには、まずplaywright-goというライブラリを利用しなければなりません。
以下のコマンドを使用してインストールできます。
go get github.com/playwright-community/playwright-goまた、クロウラーを実行するブラウザの依存関係をインストールする必要があります。以下のコマンドを使用して簡単にインストールできます。
go run github.com/playwright-community/playwright-go/cmd/playwright@latest install --with-depsPlaywrightを利用したクロールの実装
それでは実際にクロールをしてみましょう。
簡単に現在のブログをクロールしてみます。
コードが長いため、順序に従って説明します。
1. Playwrightセットアップ
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
defer pw.Stop()
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Headless: playwright.Bool(true), // false の場合、ブラウザが見える
})
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
defer browser.Close()
page, err := browser.NewPage(playwright.BrowserNewPageOptions{
UserAgent: playwright.String("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"),
})
if err != nil {
log.Fatalf("could not create page: %v", err)
}
defer page.Close()まず、playwright.Run()関数はplaywrightインスタンスを生成します。このインスタンスはブラウザを実行しページを生成するのに使用されます。
playwright.BrowserType.Launch()関数はブラウザを実行します。playwright.BrowserType.Launch()関数は
playwright.BrowserTypeLaunchOptions構造体を引数に受け取りますが、ここでHeadlessオプションをtrueに設定すると、ブラウザが見えない状態で実行されます。
その他にも様々なオプションを指定することができますが、詳細は公式ドキュメントを参考にしてください。ただし説明はJavaScript を基準にしているため、Goで使用する際は関数に直接入って注釈を見るなどの方法を使用する必要があります。
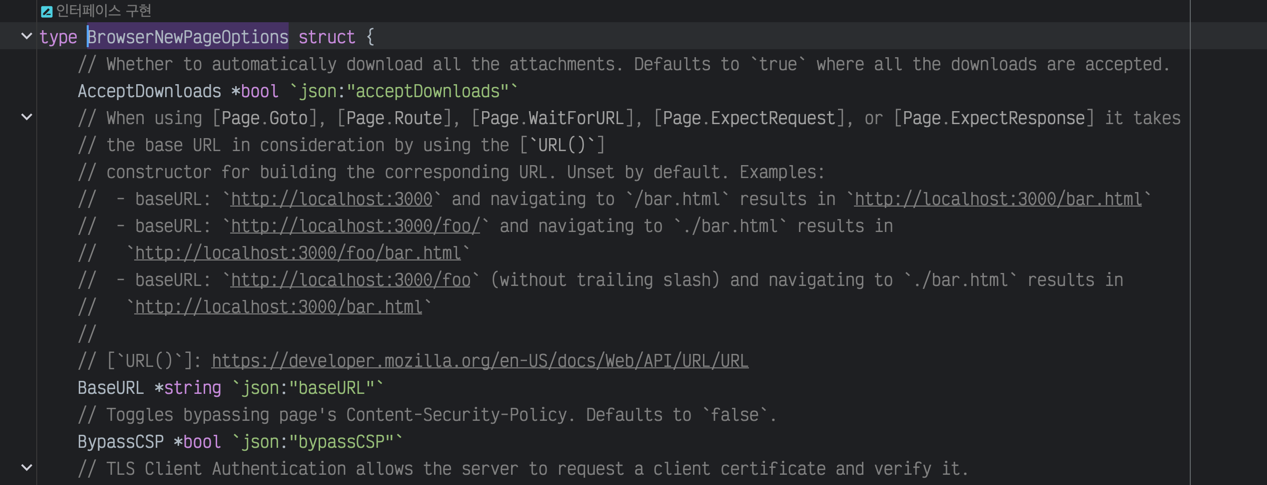
ブラウザオプションの注釈参照
browser.NewPage()関数は新しいページを生成します。playwright.BrowserNewPageOptions構造体を引数に受け取り、ここでUserAgentオプションはブラウザの
ユーザーエージェントを設定します。
一般的に多くのサイトでユーザーエージェントを確認します。特にボットなどをブロックしたり、一部のJavaScriptの実行を防ぐ場合がこれに該当します。
筆者がMozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3
のようにユーザーエージェントを設定した理由は、まるで実際のブラウザでアクセスしているかのように見えるようにするためです。
2. クロール
ではクロールをしてみましょう。
一番多く使われる関数が出てくる予定なので、一つずつ解説しながら使用する方法を説明します。
Goto: URLベースのページ移動
response, err := page.Goto("https://yangtaeyoung.github.io/blog", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateLoad,
})
if err != nil {
log.Fatalf("could not goto: %v", err)
}Gotoはpageから派生した関数で、指定されたページへ移動します。playwright.PageGotoOptions構造体を引数に取り、WaitUntilオプションはページがロードされるまで待つ
オプションです。
オプションによってplaywright.WaitUntilStateLoad, playwright.WaitUntilStateNetworkidle,
playwright.WaitUntilStateDomcontentLoadedなどがあります。
ここで筆者はplaywright.WaitUntilStateNetworkidleをよく使用していました。このオプションはネットワークがこれ以上リクエストを行わない状態になるまで待つオプションです。
筆者の場合、クライアントサイドレンダリングをしているページでは単にLoadだけを使用すると実際の内容が完全にロードされない場合があったため、これを使用しました。
例示ではplaywright.WaitUntilStateLoadを使用していますが、私のブログは静的ページなので、別にJavaScriptを待つ必要がないからです。
Locator: 要素を探す
次にクロールの花と言える要素探しです。PlaywrightではLocator関数を用いて様々な方法で要素を探すことができます。
まず私のブログのカテゴリーページです。星形が入ったカテゴリーヘッダーをすべて取得することを目標にしてみましょう。
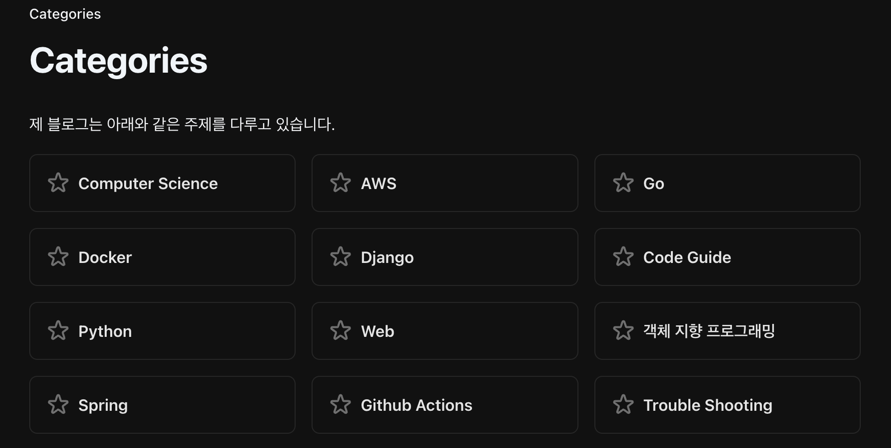
まず目的の要素を一つ見つけて右クリック - 検査ボタンを押します。
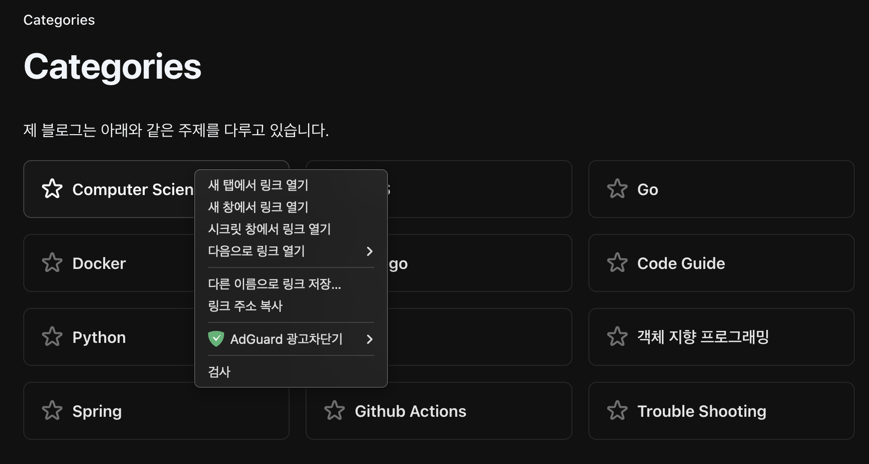
ソースコードが出てきて、各カテゴリの規則性がどうなっているのか調べなければなりません。
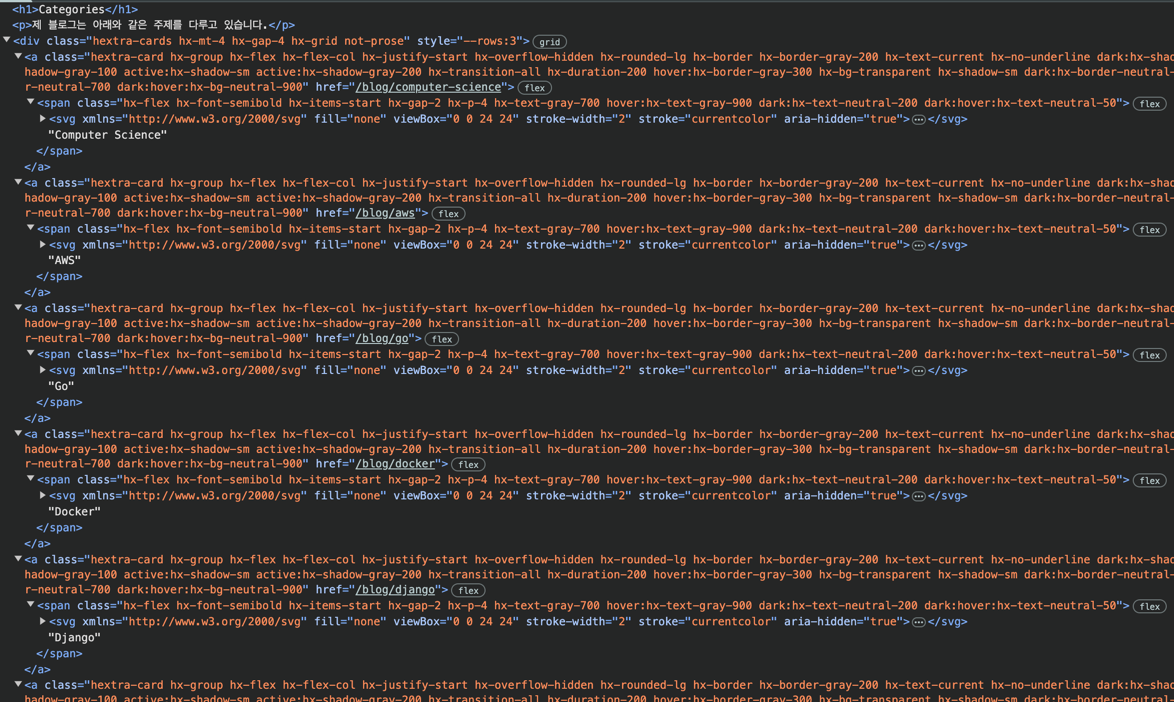
タイトルはすべてdivタグの下、aタグの下、spanタグに入っています。
ただし、ちょっと考えてみると、そのような場合は非常に多いでしょうから、もう少し具体的な規則性を見つける必要があります。
クラスを見てみると、divタグにはhextra-cardsが、aタグにはhextra-cardがあります。
他の要素を見てみると、他の規則性は見えません。
それでは探すべきものは次の通りです。
`hextra-cards`クラスを持ったdivタグの下の`hextra-card`クラスを持ったaタグの下のspanタグこれをコードに移してみましょう。
titleElements, err := page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span").All()
if err != nil {
log.Fatalf("could not find elements: %v", err)
}
}page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span")のようにLocatorはチェイン可能です。これはdiv.hextra-cards
を見つけ、その下のa.hextra-cardを見つけ、その下のspanを見つけることを意味します。
単一のLocatorを使用することも可能ですが、私はカテゴリ全体を持ってきたいので、All()を使用してマッチしたすべてのLocatorを持ってきてtitleElementsに保存しました。
それではタイトルを抽出してみましょう。タイトルを見ると問題があります。

上のように星を表現するために小さなsvgタグが入っています。
単にInnerHTMLを使用するとsvgタグまで一緒に出てきてしまいます。これはタイトルだけを抽出するためにタグを除去しなければならないなどの努力が必要です。
このような場合が多かったのでしょうか、幸いにもplaywrightでは内部のテキストだけを取得するInnerText()関数を提供しています。これを使ってtitleだけを抽出すると次のようになります。
titles := make([]string, len(titleElements))
for _, titleElement := range titleElements {
var title string
title, err = titleElement.InnerText()
if err != nil {
log.Fatalf("could not get inner text: %v", err)
}
titles = append(titles, title)
}
slog.Info("Success Crawled Titles", "titles", titles)すると次のようなコードを得ることができます。
2025/02/14 02:00:13 INFO Success Crawled Titles titles="[ Computer Science AWS Go Docker Django Code Guide Python Web オブジェクト指向プログラミング Spring Github Actions トラブルシューティング]"素晴らしいことにカテゴリーのタイトルがしっかりクロールされました。
この他にもよく使われる関数群があり、次の通りです。
| 関数名 | 説明 |
|---|---|
GetAttribute() | 要素の属性を取得します。例えば、Aタグ内のhref属性の値を知りたい場合にはこの関数を用います。 |
Click() | 要素をクリックします。特定のリンクに移動する必要があるのですが、Javascriptでリンクを知ることができない場合には、クローラーにクリックを指示することができます。 |
InnerHTML() | 要素の内部HTMLを取得します。 |
IsVisible() | 要素が見えるかどうか確認します。要素が全く無いか、display属性がnoneの場合にはtrueを返します。 |
IsEnabled() | 要素が有効かどうか確認します。 |
Count() | 要素の数を返します。 |
筆者は単純なクロールを中心に行ったせいか、InnerText、InnerHTML、GetAttributeを主に使用しました。その他にも非常に多くの関数がありますが、コードを少し眺めるだけでも分かりやすく説明されていますし、関数名も馴染みのあるものが多く、使用するのはそれほど難しくないでしょう。
最近はGPTがよく説明してくれます。
オートコンプリートで見つかる関数リストには非常に多くの関数があります。
全体コード
筆者のカテゴリを持ってくるために書いた全体コードを共有します。このコードを多く回して筆者のブログ訪問数が急増することを期待してみます 🤣
package main
import (
"log"
"log/slog"
"github.com/playwright-community/playwright-go"
)
func main() {
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
defer pw.Stop()
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Headless: playwright.Bool(true), // false の場合、ブラウザが見える
})
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
defer browser.Close()
page, err := browser.NewPage(playwright.BrowserNewPageOptions{
UserAgent: playwright.String("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"),
BypassCSP: playwright.Bool(true),
})
if err != nil {
log.Fatalf("could not create page: %v", err)
}
defer page.Close()
if _, err := page.Goto("https://yangtaeyoung.github.io/blog", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateNetworkidle,
}); err != nil {
log.Fatalf("could not goto: %v", err)
}
titleElements, err := page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span").All()
if err != nil {
log.Fatalf("could not find title elements: %v", err)
}
titles := make([]string, len(titleElements))
for _, titleElement := range titleElements {
var title string
title, err = titleElement.InnerText()
if err != nil {
log.Fatalf("could not get inner text: %v", err)
}
titleElement.
titles = append(titles, title)
}
slog.Info("Success Crawled Titles", "titles", titles)
}終わりに
Playwrightはテスト自動化で多く使われているようですが、どうもGolangサイドではあまり使用されていないようです。(特に韓国では非常にこのような資料が少ないような気がしました)
Goでもクロールが非常に自由になり、プロジェクト初期にはデータ収集が難しいのですが、このようなツールを活用すれば、大規模なデータ分析やAIに必要なデータ収集も簡単にできるでしょう。