Explorons l'architecture événementielle du point de vue d'un serveur API
Il arrive parfois que, lors du développement, la réponse d’une API soit lente. Dans de tels cas, on peut optimiser le code ou appliquer un cache pour accélérer la réponse de l’API.
Bien sûr, ces méthodes sont excellentes si elles fonctionnent et sont la meilleure solution, mais parfois, certaines tâches prennent inévitablement beaucoup de temps.
Prenons l’exemple d’AWS : supposons qu’il y ait une API spécifique pour démarrer une machine EC2. Cette tâche, le démarrage d’une machine EC2, prend pas mal de temps. Peut-on vraiment réduire ce temps simplement en optimisant le code ?
Allumer ou éteindre un ordinateur prendra toujours du temps, peu importe l’optimisation (d’ailleurs, même l’ordinateur de l’auteur met bien 30 secondes pour démarrer).
Si on traite cela avec une API synchrone, on peut le configurer comme suit.
Voyons cela en utilisant le langage Go :
package main
import "net/http"
func StartEc2Handler(w http.ResponseWriter, r *http.Request) {
// ...
// Code pour démarrer la machine EC2
// ...
w.Write([]byte(`{"result": "success"}`)) // Réponse au format JSON
}Le code a été écrit sans distinction de couche. Dans le code réel, il y aurait des couches telles que service, repository, etc.
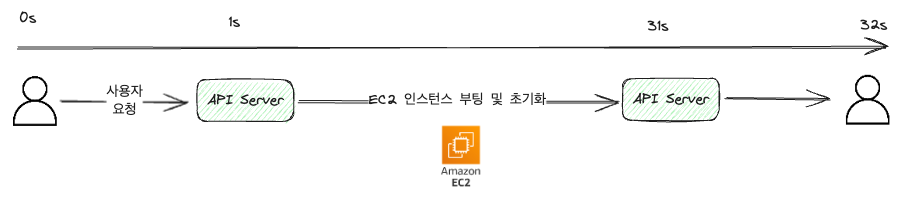
Dans l’exemple illustré, pour simplifier, nous supposons que la communication entre l’utilisateur et le serveur prend une seconde (en réalité, cela serait beaucoup plus court en millisecondes).
Comme montré sur l’image, on reçoit une requête API, on traite le démarrage de la machine EC2 et on renvoie le résultat.
Dans une méthode synchrone, on répond à la requête une fois la tâche terminée, ce qui peut interrompre le processus si on quitte la page ou on rafraîchit.
Du point de vue de l’utilisateur, cela signifie devoir regarder un écran de chargement pendant 32 secondes.
Ce qui pourrait être perçu comme une horreur.
Pour éviter les interruptions, un message d’avertissement peut être affiché. Cependant, il est impossible d’empêcher l’utilisateur d’appuyer sur “OK”.
Dans le cas de l’auteur, il fallait environ 10 secondes pour télécharger un produit sur trois services externes dans un service B2B, et l’opération était généralement effectuée par lot de 100 à 200, ce qui rendait l’attente de plus de 10 minutes insupportable.
Ne touchez pas à l’ordinateur pendant 10 minutes.-> Est-ce supportable ?
Solution 1. Rendre l’API asynchrone
Avant de passer au traitement événementiel, on peut rendre l’API asynchrone.
Comme le Go facilite le traitement de la concurrence, voici comment cela pourrait se faire :
package main
import "net/http"
func StartEc2Handler(w http.ResponseWriter, r *http.Request) {
// ...
go func() {
// Code pour démarrer la machine EC2
// Code pour notifier les utilisateurs du succès/échec
}()
// ...
w.WriteHeader(http.StatusAccepted) // 202 Accepted : Requête reçue, le travail a commencé
}Ce code traite le démarrage de la machine EC2 avec une goroutine et renvoie 202 Accepted pour indiquer que la requête a été reçue et que le travail a commencé.
Cela réduit considérablement le temps entre la requête et la réponse, comme suit :
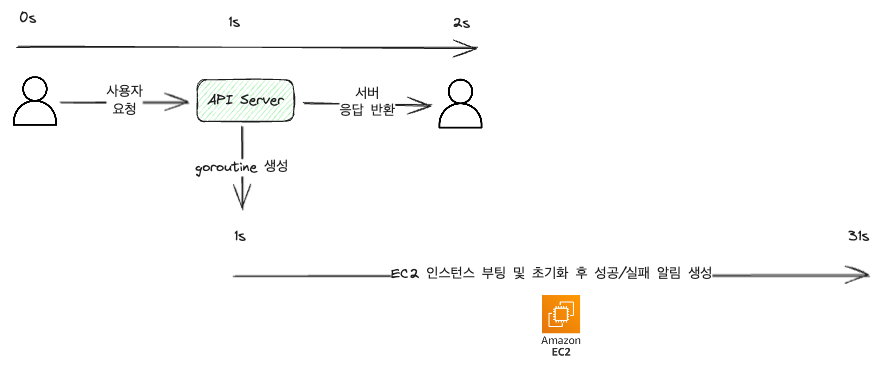
On voit que la requête utilisateur ne prend que 2 secondes environ, et la réponse est très rapide. Cependant, un nouveau code de notification a été ajouté.
En effet, 202 n’est qu’un accusé de réception et ne garantit pas que la tâche est accomplie.
Ainsi, pour informer le client du succès/échec de la tâche, des notifications ou des statuts doivent être ajoutés, même si cela n’est pas absolument nécessaire du point de vue du code pure :
Un développeur devrait néanmoins considérer l’ajout de notifications pour informer l’utilisateur, car le manque de feedback nuit à l’expérience utilisateur et il est préférable d’inclure les notifications dès que possible.
Une victoire ?
Pas exactement. Le monde est plein de contraintes et de problèmes divers.
À mesure que le code se complexifie, divers problèmes surgissent, et l’auteur a rencontré les trois suivants :
- Les tâches asynchrones génèrent généralement une charge haute (sinon, elles seraient traitées de manière synchrone sans souci). Aussi, une forte affluence sur l’API peut causer une surcharge du serveur.
- Lorsque les tâches sont interrompues pour des raisons telles que des déploiements ou des catastrophes naturelles, leur restauration est difficile, et aucune notification n’est envoyée à l’utilisateur.
- Si l’API fait appel à des services externes, des limites de taux (Rate Limit) peuvent causer un échec de traitement lorsque les demandes affluent, résultant en une réponse de type 429 Too Many Requests.
Solution 2. Traiter avec une architecture basée sur des événements (Event Driven Architecture)
Une architecture basée sur des événements signifie simplement traiter les tâches en fonction des événements.
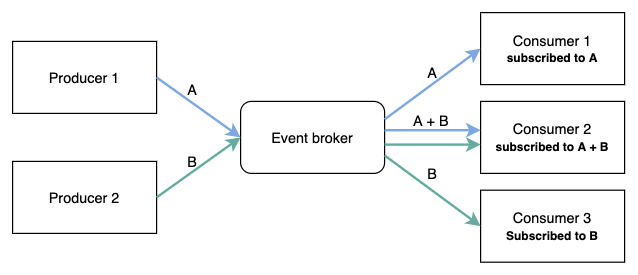
Un intermédiaire Broker d’événements se situe au milieu. Le producteur émet l’événement et le consommateur l’abonne pour le traiter.
Les Brokers d’événements sont souvent Kafka, RabbitMQ, AWS SNS, etc., tandis que les producteurs et les consommateurs échangent des événements via ceux-ci.
Le consommateur se charge du travail effectif (comme démarrer une machine EC2), et le producteur, après réception de la requête, émet un événement puis renvoie 202 Accepted.
Voyons quelques exemples de code :
Dans l’exemple suivant, nous utilisons RabbitMQ pour émettre et s’abonner à des événements :
package main
import (
"net/http"
amqp "github.com/rabbitmq/amqp091-go"
)
func PublishStartEc2EventHandler(w http.ResponseWriter, r *http.Request) {
// Se connecter à rabbitmq et récupérer un canal
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
w.Write([]byte(`{"result": "rabbitmq connection error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
ch, err := conn.Channel()
if err != nil {
w.Write([]byte(`{"result": "rabbitmq channel error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
// Publier l'événement
event, err := json.Marshal(Event{
Code: "START_EC2",
RequestID: "some_uuid",
Body: "some_body",
})
if err != nil {
w.Write([]byte(`{"result": "json marshal error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
if err = ch.PublishWithContext(
r.Context(),
"",
"aws-event-queue",
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: event,
}); err != nil {
w.Write([]byte(`{"result": "rabbitmq publish error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
w.WriteHeader(http.StatusAccepted)
}Le code est un peu long, mais l’important est le rôle de cette API.
Cette API suit les étapes suivantes : connexion à RabbitMQ -> créer un objet événement -> le sérialiser en JSON -> mettre l’objet dans le corps de l’événement et l’émettre.
En pratique, la connexion à Queue est généralement partagée à l’initialisation de l’application, ce qui rend les connexions redondantes ; toutefois, pour éviter toute confusion sur
conn.Channel(), cette partie est incluse pour faciliter la compréhension.
Le code du consommateur peut être très long selon ses fonctionnalités, d’où son omission dans l’illustration suivante :
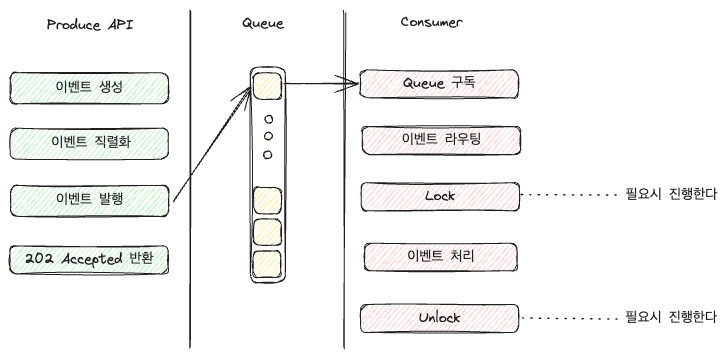
Selon la configuration, l’attribution des rôles de routing est elle-même variable ; on peut gérer chaque événement dans une queue dédiée ou, comme montré, chaque Application face à ces événements et les route.
Si la taille et les responsabilités du consommateur augmentent, on peut envisager d’ajouter une couche distincte pour la gestion de ces tâches.
Pourquoi verrouiller (Lock) ?
Dans une architecture événementielle, on peut choisir d’activer un verrou à une étape de la consommation.
Le verrou (Lock) peut être un RedisLock, DB Lock, etc., et sert à gérer la synchronisation des ressources.
Un verrou empêche les autres consommateurs de traiter un événement ou une queue donnée jusqu’à ce que celui-ci soit libéré. Par exemple :
- Dans un environnement à conteneurs multiples, plusieurs consommateurs sont présents. Sans verrou (Lock), les autres conteneurs travaillant sur la même queue ne se détectent pas, et l’effet volumétrique diminue. Dans mon cas, j’ai utilisé le verrou pour limiter le nombre d’événements traités simultanément.
- Lorsque plusieurs consommateurs gèrent le même événement, des doublons peuvent apparaître, donc utilisation du verrou.
- Généralement, les services externes limitent le nombre de requêtes simultanément traitées pour éviter leurs charges. Dans ce cas, avec une limite fixée à 2 requêtes par seconde, un seul appel simultané est autorisé, nécessitant un verrou.
Chaîne d’événements (Event Chain)
L’intérêt des chaînes d’événements réside dans la capacité à lier plusieurs événements ensemble.
For instance, in an EC2 handler, there are two tasks involved:
- Activation d’une machine EC2
- Création d’une alerte pour la machine EC2 activée
Sa conversion en chaîne d’événements donnera :
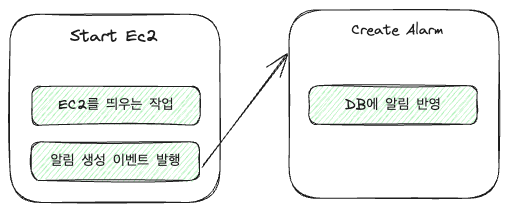
En code, cela pourrait se traduire par quelque chose de très simple :
func StartEc2Event(args any) {
// Activation de la machine EC2
// ... Some code
// Émission de l'événement CreateAlarm
ch.PublishWithContext(
r.Context(),
"",
"aws-event-queue",
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: event, // Admettons que l'opération a réussi
})
}
func CreateAlarm(args any) {
// Générer une alerte
}La fonction, bien que dépendante d’un Consumer, montre que StartEc2Event consomme l’événement pour en émettre un nouveau. Ainsi, l’ordre des tâches devient facile à gérer.
Si les événements sont bien standardisés, leur réutilisation sera fréquente. Par exemple : CreateAlarm sera applicable dans de nombreux cas, pas uniquement dans celui-ci.
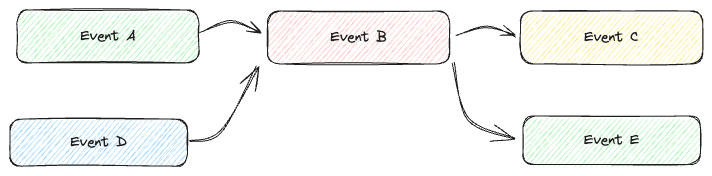
En termes de productivité, ne pas avoir à redévelopper des événements déjà réalisés est un énorme atout.
Désavantages
On pourrait penser que les exemples graphiques paraissent simples, mais dans la pratique et selon les besoins, le code peut devenir très complexe.
À mesure que la profondeur des chaînes augmente, il devient difficile de suivre le flux, et l’analyse des relations entre événements lors du débogage devient compliquée.
Par conséquent, il est crucial de documenter avec précision les relations entre événements et leurs flux.
Conclusion
L’architecture basée sur des événements est puissante si bien maîtrisée. En ajustant le nombre d’API consommées, la charge serveur peut être réduite et la réutilisation est optimisée par les chaînes d’événements.
Elle améliore l’expérience de l’utilisateur grâce à des réponses plus rapides aux requêtes, lui permettant d’effectuer d’autres tâches parallèlement. Cependant, pour regrouper des transactions lors de la surveillance, une configuration spécifique est nécessaire, et des erreurs dans la création d’événements peuvent conduire à une complexité bien plus élevée qu’avec des API synchrones simples.
C’est pourquoi je pense qu’il est essentiel, lors de l’intégration de l’architecture événementielle, d’établir des conventions et de les documenter clairement à l’avance avec l’équipe.