Application de Redis Cache dans Spring Boot
Bien qu’un peu en retard, j’ai eu l’occasion de faire un test de charge API en utilisant un outil appelé Locust. Je souhaite partager mon expérience d’application de Redis Cache pour résoudre le retard de réponse de certaines API qui est survenu à ce moment-là.
Qu’est-ce qu’un Cache ?
Un cache est une zone mémoire qui permet d’accéder rapidement à des données ou valeurs copiées à l’avance.
Fondamentalement, comme les RDB sont stockés sur le disque, il est possible de récupérer des données à une vitesse bien plus rapide avec Redis, qui est stocké en mémoire, par rapport aux RDB.
Bien que le flux puisse varier selon la stratégie de cache, en se basant sur la stratégie de cache générale “Look-Aside Cache”, l’explication est la suivante:
Cache Hit
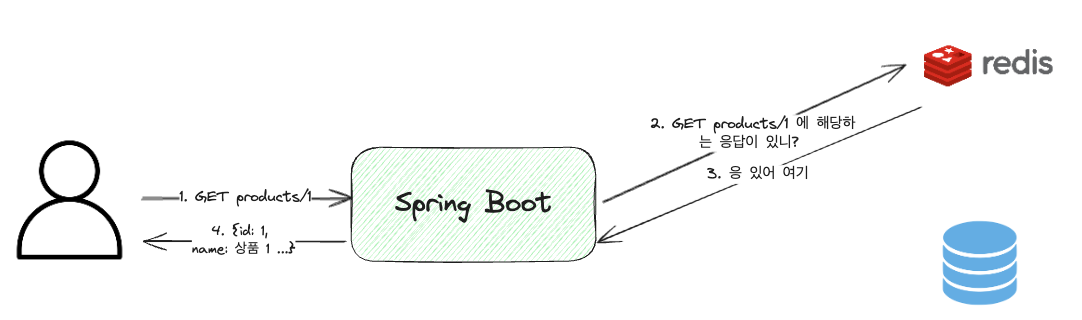
On parle de Cache Hit lorsque les données existent dans le cache. Dans ce cas, les données sont récupérées du cache et donc, le temps pris pour les récupérer est très rapide.
Cache Miss
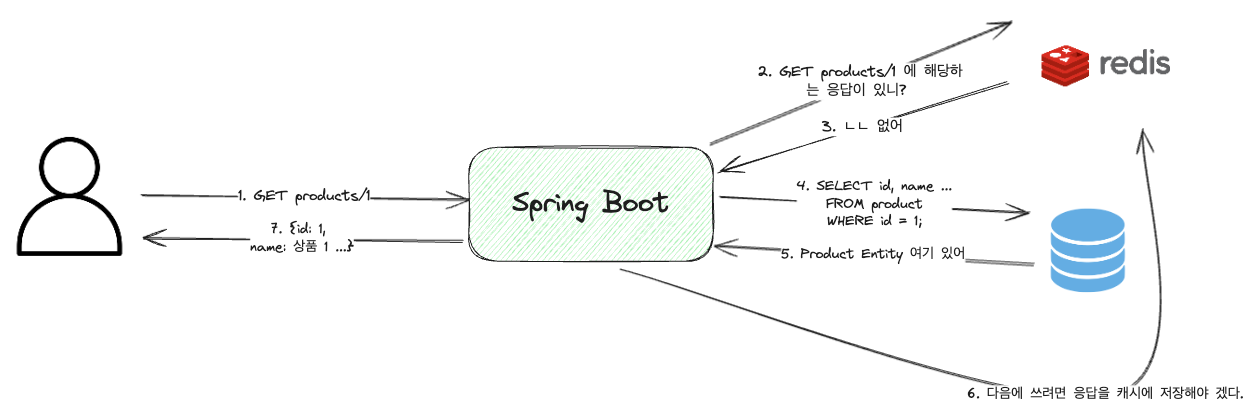
On parle de Cache Miss lorsque les données n’existent pas dans le cache. Dans ce cas, les données sont récupérées de la base de données ou d’autres dépôts, tandis que Redis vérifie les données, les récupère depuis la DB et les réenregistre dans Redis après la réponse.
Ainsi, dans ce cas, il peut en fait être plus lent que dans l’absence de cache.
Pourquoi utiliser Redis comme cache
Redis, l’acronyme de Remote Dictionary Server, est une base de données open-source avec une structure clé-valeur basée en mémoire.
On peut effectivement le voir comme une base de données.
En général, même lorsqu’on récupère des données à partir d’un RDB, si l’indexation est bien faite, il n’y a pas de gros problème pour récupérer rapidement les données.
Cependant, les résultats de recherches, la pagination, etc., nécessitent souvent un grand nombre d’opérations, donc ces résultats sont stockés en cache pour être réutilisés.
Application de Redis Cache dans Spring Boot
1. Ajouter les dépendances
Tout d’abord, il est nécessaire d’ajouter les dépendances pour utiliser Redis.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'2. Ajouter la configuration Redis
Il faut ajouter la configuration pour la connexion à Redis.
@RequiredArgsConstructor
@Configuration
@EnableRedisRepositories
public class RedisConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(host, port);
}
@Bean
public RedisTemplate<String, Object> redisTemplate() {
var redisTemplate = new RedisTemplate<String, Object>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(redisConnectionFactory());
return redisTemplate;
}
}D’abord, redisConnectionFactory() crée une connectionFactory pour la connexion à Redis et utilise LettuceConnectionFactory.
Les clients Java communs pour se connecter à Redis sont principalement Jedis et Lettuce, mais on dit que Lettuce est plus rapide car il supporte le traitement asynchrone et utilise Netty.
redisTemplate() est un Template pour stocker et récupérer des données dans Redis. Il a configuré les Serializers pour les clés et les valeurs via setKeySerializer(), setValueSerializer().
Nous avons utilisé simplement le StringRedisSerializer.
3. Ajouter la configuration Cache
@Configuration
@EnableCaching
public class CacheConfig {
private Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer() {
var objectMapper = new ObjectMapper();
objectMapper.registerModule(new JavaTimeModule());
objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
objectMapper.enable(MapperFeature.ACCEPT_CASE_INSENSITIVE_ENUMS);
objectMapper.configure(
JsonReadFeature.ALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER.mappedFeature(), true);
objectMapper.activateDefaultTyping(
objectMapper.getPolymorphicTypeValidator(),
ObjectMapper.DefaultTyping.EVERYTHING,
JsonTypeInfo.As.WRAPPER_OBJECT
);
objectMapper.setSerializationInclusion(JsonInclude.Include.NON_NULL);
return new Jackson2JsonRedisSerializer<>(objectMapper, Object.class);
}
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheConfiguration defaultCacheConfig =
RedisCacheConfiguration.defaultCacheConfig()
// Configurer le TTL (par exemple : 60 secondes)
.entryTtl(Duration.ofSeconds(60))
// Empêcher la mise en cache des valeurs nulles
.disableCachingNullValues()
// Sérialisation de la clé
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new StringRedisSerializer()))
// Sérialisation de la valeur
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
jackson2JsonRedisSerializer()));
return RedisCacheManager
.builder(connectionFactory)
.cacheDefaults(defaultCacheConfig)
.build();
}
}Une classe CacheConfig a été créée pour configurer le cache.
- La méthode
jackson2JsonRedisSerializer()crée unJackson2JsonRedisSerializeret configure la sérialisation JSON en utilisant ObjectMapper. Elle a enregistréJavaTimeModuleparregisterModule(), pour sérialiser et désérialiser correctement les API Date/Time de Java 8. Si cette configuration n’est pas établie, l’erreur suivante peut se produire lors de la sérialisation d’objets du packagejava.time:com.fasterxml.jackson.databind.exc.InvalidDefinitionException: No serializer found for class java.time.LocalDateTime and no properties discovered to create BeanSerializer (to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS)disable()a été utilisé pour désactiverWRITE_DATES_AS_TIMESTAMPS, empêchant la sérialisation des objets Date/Time en tant que timestamps.enable()a été utilisé pour activerACCEPT_CASE_INSENSITIVE_ENUMS, permettant d’ignorer la distinction majuscule/minuscule pour les Enums.configure()a activéALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER, permettant l’échappement des barres obliques inverses dans les chaînes JSON.activateDefaultTyping()a été employé pour définirEVERYTHING, sérialisant des informations de type pour tous les objets.- Cela ajoute le champ
@classlors de l’enregistrement JSON pour stocker les informations de type pour tous les objets. Ceci est consulté lors de la désérialisation des objets pour les informations de type.
Cependant, en cas de modification de l’emplacement des types, cela peut causer des problèmes de reconnaissance du type. Il est donc crucial de purger les caches lors du déploiement pour pallier ce problème.
- Cela ajoute le champ
setSerializationInclusion()a été utilisé pour définirNON_NULL, empêchant la sérialisation des champs contenant des valeurs nulles.
- La méthode
cacheManager()crée unRedisCacheManager, responsable de la configuration détaillée lors du stockage et de la récupération du cache depuis Redis.defaultCacheConfig()permet de charger la configuration cache par défaut, avecentryTtl()configurant le TTL du cache. Dans cet exemple, il est réglé à 60 secondes. (Une durée trop longue peut entraîner une incohérence entre le cache et les données réelles, donc configurez le temps de cache et la stratégie de mise à jour avec soin.)
4. Utilisation de Cacheable, CacheEvict, CachePut
@Cacheable
L’annotation @Cacheable sauvegarde le résultat d’une méthode dans le cache et retourne le résultat mis en cache lors d’appels identiques.
@RestContoller
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/products/{id}")
@Cacheable(value = "product", key = "#id")
public Product getProduct(@PathVariable Long id) {
return productService.getProduct(id);
}
}L’annotation @Cacheable est ajoutée à des méthodes employant le cache, configurant le nom du cache via value et la clé de cache via key.
@CacheEvict
L’annotation @CacheEvict supprime les données du cache lors de l’appel de la méthode concernée.
Dans des cas de consultation de listes comme ici, il peut être difficile de déterminer quelle donnée influence la consultation, générant ainsi une stratégie de suppression du cache.
Même pour les API de consultation unique, il est sûr de supprimer le cache lorsque les données pour un certain ID changent.
@RestContoller
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/products/{id}")
@Cacheable(value = "product", key = "#id")
public Product getProduct(@PathVariable Long id) {
return productService.getProduct(id);
}
@PostMapping("/products")
@CacheEvict(value = "product", allEntries = true) # Si aucune API de consultation de liste n'existe, il n'est pas nécessaire de le spécifier.
public Product createProduct(@RequestBody Product product) {
return productService.createProduct(product);
}
}L’annotation @CacheEvict est ajoutée aux méthodes supprimant le cache, avec value configurant le nom du cache et allEntries déterminant la suppression de tous les caches.
- Pour un cas de consultation unique,
keypeut être employé pour supprimer uniquement le cache pour une clé spécifique.
@CachePut
L’annotation @CachePut sauvegarde le résultat d’une méthode dans le cache, mais contrairement à @Cacheable, elle appelle toujours la méthode et ne retourne pas simplement le résultat mis en cache.
@RestContoller
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/products/{id}")
@Cacheable(value = "product", key = "#id")
public Product getProduct(@PathVariable Long id) {
return productService.getProduct(id);
}
@GetMapping("/products")
@Cacheable(value = "product")
public ListProductsResponse listProducts() {
return productService.listProducts();
}
@PostMapping("/products")
@CacheEvict(value = "product", allEntries = true) # Si aucune API de consultation de liste n'existe, il n'est pas nécessaire de le spécifier. Si une consultation unique existe, utiliser CachePut peut être une solution.
public Product createProduct(@RequestBody Product product) {
return productService.createProduct(product);
}
@PutMapping("/products/{id}")
@CachePut(value = "product", key = "#id")
public Product updateProduct(@PathVariable Long id, @RequestBody Product product) {
return productService.updateProduct(id, product);
}
}L’annotation @CachePut est ajoutée aux méthodes pour mettre à jour le cache, avec value pour le nom du cache et key pour la clé du cache.
Doit-on toujours utiliser un cache ?
Plus il y a de données, plus le calcul est complexe, plus le cache est avantageux à utiliser, surtout pour les réponses identiques répétées.
Les données statiques telles que les images ou les vidéos sont très peu modifiées, donc la majorité des navigateurs et des CDN utilisent le cache.
Cependant, dans le cas de données fréquemment mises à jour ou pour des données nécessitant une actualité immédiate (comme le solde d’un compte, les informations de livraison, etc.), il est souvent préférable de ne pas utiliser le cache car le résoudre l’incohérence des données peut être plus difficile.
En fin de compte, l’utilisation ou non du cache dépend des caractéristiques des données, des modèles de comportement des utilisateurs, des caractéristiques du service, etc. De plus, les temps de cache, stratégie de mise à jour, etc., doivent être soigneusement examinés.