Explorons le crawling avec Playwright en Golang
Il existe plusieurs façons de collecter des données, mais la plus courante est d’utiliser une technique appelée le crawling.
Le terme crawling peut se traduire littéralement par “ramper”. Le web crawling consiste à naviguer sur le web pour collecter des informations.
Outils
On utilise souvent Python, non seulement pour sa simplicité, mais aussi parce qu’il existe de nombreuses bibliothèques spécialisées dans le crawling. Les outils les plus connus sont BeautifulSoup, Selenium, Scrapy, etc.
Récemment, un outil appelé Playwright a été créé. Bien qu’il soit principalement utilisé pour l’automatisation des tests, il peut également être utilisé pour le crawling. Contrairement à BeautifulSoup qui sert seulement de parseur, Playwright contrôle les actions basées sur un navigateur réel, rendant son utilisation utile lors de l’exécution de JavaScript ou le crawling de SPA (Single Page Applications).
Cet outil supporte plusieurs langages, notamment Node.js, Python, Go. Nous allons l’utiliser avec Go.
Installation de Playwright
Pour utiliser Playwright en Go, il faut d’abord installer la bibliothèque playwright-go.
On peut l’installer avec la commande suivante :
go get github.com/playwright-community/playwright-goVous devez également installer les dépendances du navigateur utilisé par le crawler. Vous pouvez le faire simplement avec la commande suivante :
go run github.com/playwright-community/playwright-go/cmd/playwright@latest install --with-depsImplémentation du crawling avec Playwright
Passons maintenant à l’implémentation pratique du crawling.
Nous allons tenter de crawler ce blog.
Le code étant long, je vais vous l’expliquer étape par étape.
1. Configuration Playwright
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
defer pw.Stop()
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Headless: playwright.Bool(true), // Si false, le navigateur est visible
})
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
defer browser.Close()
page, err := browser.NewPage(playwright.BrowserNewPageOptions{
UserAgent: playwright.String("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"),
})
if err != nil {
log.Fatalf("could not create page: %v", err)
}
defer page.Close()D’abord, la fonction playwright.Run() crée une instance de Playwright. Cette instance est utilisée pour démarrer le navigateur et créer une page.
La fonction playwright.BrowserType.Launch() lance le navigateur. Elle prend comme argument une structure playwright.BrowserTypeLaunchOptions, et l’option Headless à true rend la navigation invisible.
Vous pouvez spécifier plusieurs options ; pour plus de détails, consultez la documentation officielle. Prenez en compte que la description suit le standard JavaScript et il peut être nécessaire de consulter les commentaires dans le code Go.
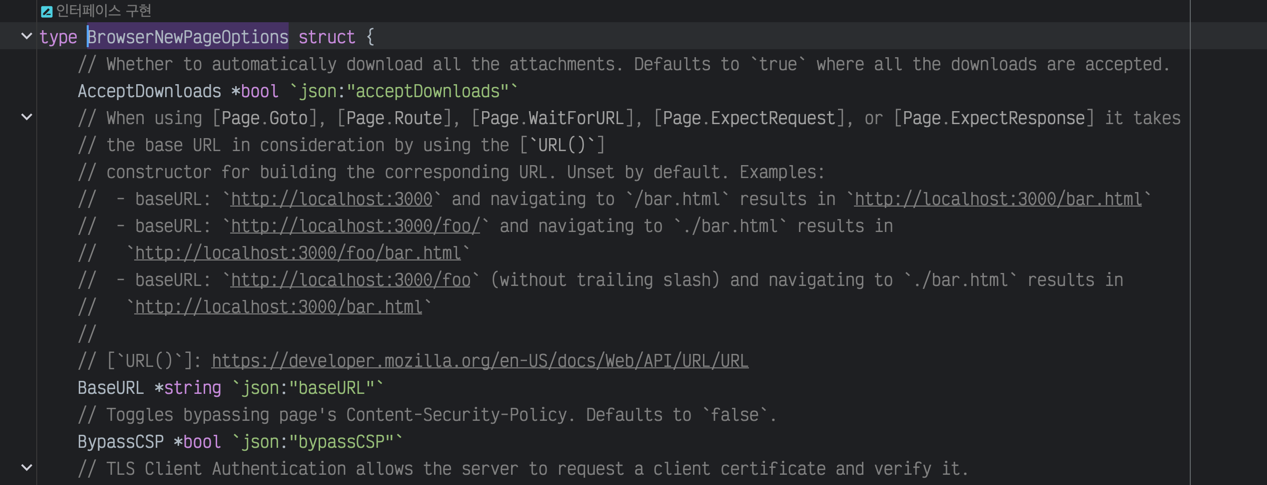
Référence des options de navigateur
La fonction browser.NewPage() crée une nouvelle page. Elle prend comme argument une structure playwright.BrowserNewPageOptions, où l’option UserAgent paramètre l’UserAgent du navigateur.
Généralement, de nombreux sites vérifient l’UserAgent. Cela est souvent utilisé pour bloquer les bots ou empêcher l’exécution de certains JavaScript.
J’ai configuré l’UserAgent à Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3
pour qu’il ressemble à une véritable connexion via navigateur.
2. Crawling
C’est parti pour le crawling.
Comme je vais présenter des fonctions essentielles, je vous expliquerai chaque étape.
Goto: Navigation vers une page via une URL
response, err := page.Goto("https://yangtaeyoung.github.io/blog", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateLoad,
})
if err != nil {
log.Fatalf("could not goto: %v", err)
}La fonction Goto dérive de page et permet de naviguer vers une page cible. Elle prend comme argument une structure playwright.PageGotoOptions, où l’option WaitUntil attend que la page soit chargée.
Les options incluent playwright.WaitUntilStateLoad, playwright.WaitUntilStateNetworkidle, ou encore
playwright.WaitUntilStateDomcontentLoaded.
J’utilise souvent playwright.WaitUntilStateNetworkidle, qui attend que le réseau ne fasse plus de requêtes.
Dans la démonstration, j’utilise playwright.WaitUntilStateLoad, car mon blog est une page statique n’ayant pas besoin d’attendre l’exécution de JavaScript.
Locator: Localisation d’un élément
Passons à la recherche d’élément, une des parties centrales du crawling. Dans Playwright, on utilise la fonction Locator pour trouver un élément de diverses manières.
Prenons l’exemple de la page de catégorie de mon blog. L’objectif est de récupérer tous les titres de catégorie étoilés.
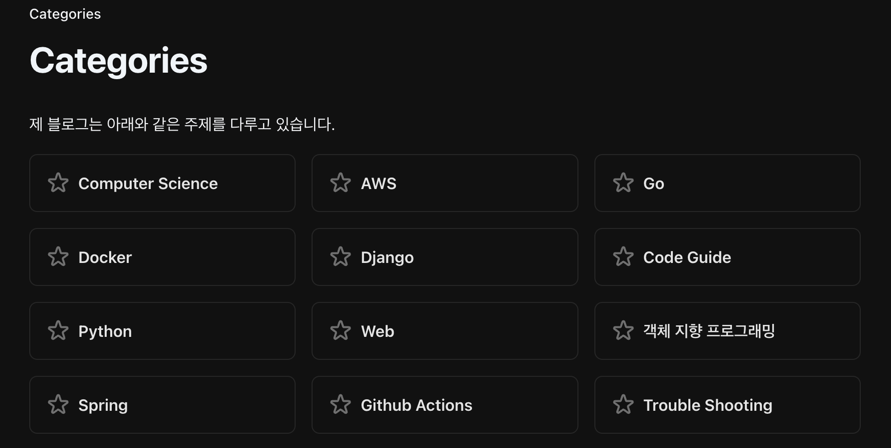
Commencez par sélectionner un élément désiré, clic droit - bouton Inspecter.
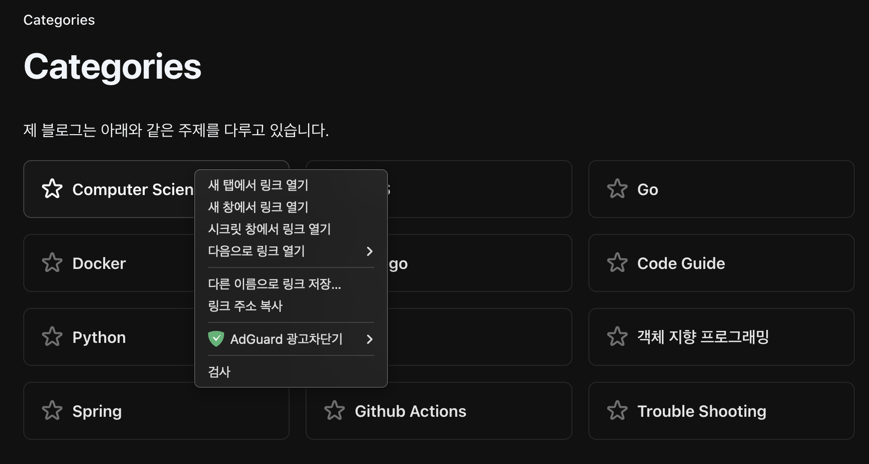
Vous verrez alors le code source, permettant d’identifier les règles de localisation des catégories.
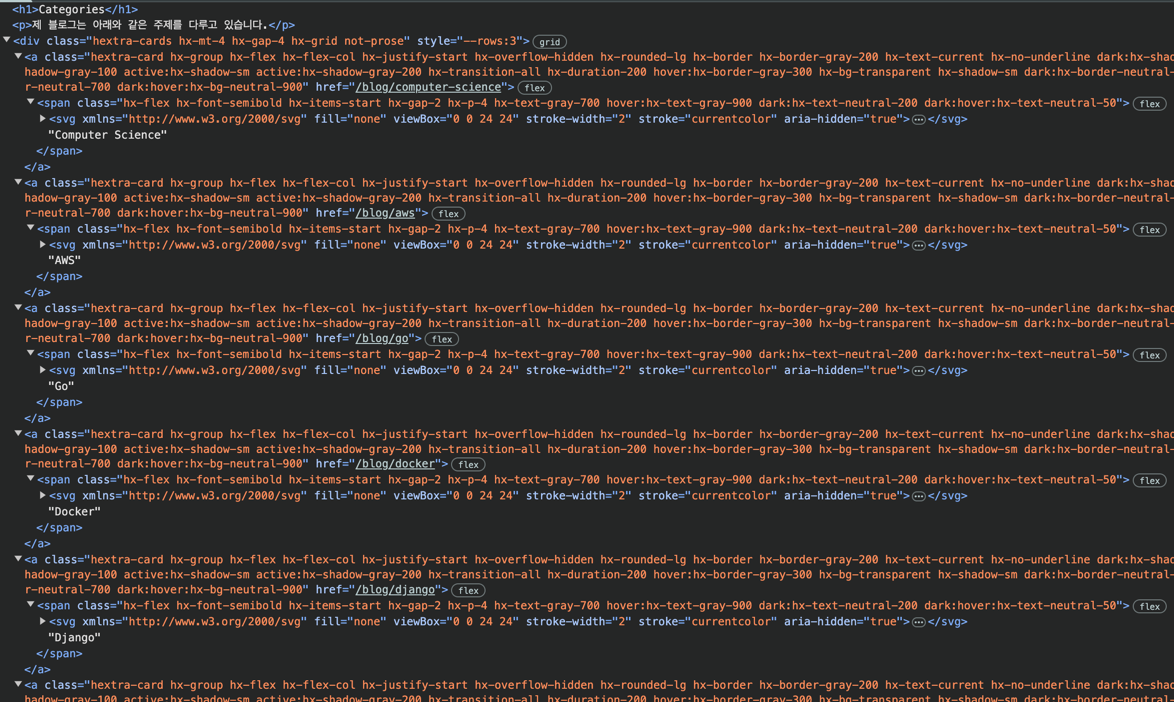
Vous remarquerez que chaque titre est contenu dans un span sous un a et sous un div.
Cependant, cela est commun, et des règles plus spécifiques sont nécessaires.
Voyons les classes, le div a la classe hextra-cards et a a la classe hextra-card.
En regardant les autres éléments, aucune autre règle ne semble évidente.
Il nous faut chercher ceci :
`Un tag div avec la classe hextra-cards, un tag a avec la classe hextra-card, et un tag span en-dessous`Voyons maintenant comment traduire cela en code
titleElements, err := page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span").All()
if err != nil {
log.Fatalf("could not find elements: %v", err)
}
}L’expression page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span") indique que le Locator est chaîné. Cela signifie qu’il identifie div.hextra-cards, puis a.hextra-card en dessous, et enfin span.
On peut utiliser un Locator seul, mais je veux extraire toutes les catégories, alors j’utilise All() pour tous les récupérer et les stocker dans titleElements.
Voyons maintenant comment extraire les titres, avec un souci à surmonter.

Comme vous le voyez, il y a un minuscule tag svg pour afficher les étoiles.
Si vous utilisez InnerHTML, le tag svg sera inclus. Pour n’extraire que les titres, une manipulation sera nécessaire.
Heureusement, Playwright propose la méthode InnerText() qui extrait seulement le texte interne. Voici comment extraire les title :
titles := make([]string, len(titleElements))
for _, titleElement := range titleElements {
var title string
title, err = titleElement.InnerText()
if err != nil {
log.Fatalf("could not get inner text: %v", err)
}
titles = append(titles, title)
}
slog.Info("Success Crawled Titles", "titles", titles)Voici ce que le code retournera :
2025/02/14 02:00:13 INFO Success Crawled Titles titles="[ Computer Science AWS Go Docker Django Code Guide Python Web 객체 지향 프로그래밍 Spring Github Actions Trouble Shooting]"Les titres des catégories ont été brillamment extraits.
Parmi les fonctions courantes, vous trouverez :
| Nom de la fonction | Description |
|---|---|
GetAttribute() | Obtient l’attribut d’un élément, par exemple la valeur de href d’un tag A. |
Click() | Clique sur un élément. Si un lien JavaScript l’empêche d’être connu, c’est utile pour guider le crawler. |
InnerHTML() | Récupère le HTML interne d’un élément. |
IsVisible() | Vérifie si un élément est visible. Si l’élément n’existe pas ou a un style display none, retourne true. |
IsEnabled() | Vérifie si un élément est actif. |
Count() | Retourne le nombre d’éléments. |
Je me suis souvent servi de InnerText, InnerHTML, GetAttribute pour du simple crawling. Il existe bien d’autres fonctions, aisément compréhensibles par leur nom et les explications, mais elles ne devraient pas représenter un grand défi d’utilisation.
De nos jours, GPT explique bien tout cela aussi.
Capture de la liste de fonctions suggérée en autocomplétion, montrant la diversité des fonctions disponibles.
Code complet
Je partage ici le code intégral que j’ai utilisé pour extraire les catégories. J’espère que cela générera une croissance exponentielle des visites sur mon blog 🤣
package main
import (
"log"
"log/slog"
"github.com/playwright-community/playwright-go"
)
func main() {
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
defer pw.Stop()
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Headless: playwright.Bool(true), // Si false, le navigateur est visible
})
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
defer browser.Close()
page, err := browser.NewPage(playwright.BrowserNewPageOptions{
UserAgent: playwright.String("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"),
BypassCSP: playwright.Bool(true),
})
if err != nil {
log.Fatalf("could not create page: %v", err)
}
defer page.Close()
if _, err := page.Goto("https://yangtaeyoung.github.io/blog", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateNetworkidle,
}); err != nil {
log.Fatalf("could not goto: %v", err)
}
titleElements, err := page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span").All()
if err != nil {
log.Fatalf("could not find title elements: %v", err)
}
titles := make([]string, len(titleElements))
for _, titleElement := range titleElements {
var title string
title, err = titleElement.InnerText()
if err != nil {
log.Fatalf("could not get inner text: %v", err)
}
titleElement.
titles = append(titles, title)
}
slog.Info("Success Crawled Titles", "titles", titles)
}Conclusion
Playwright semble être beaucoup utilisé pour l’automatisation des tests, mais il ne semble pas énormément exploité avec Golang, surtout en Corée où ces ressources semblent rares.
Désormais, le crawling avec Go est très accessible, et avec ces outils, même l’acquisition de données pour le Big Data ou l’AI peut devenir facile au début d’un projet.