Understanding Event-Driven Architecture from the Perspective of an API Server
Occasionally, while developing, you might find API responses to be slow. In such cases, you could try optimizing your code or applying caching to speed up the API response.
Of course, these are good methods if they work and are optimal, but sometimes there are tasks that are inevitably time-consuming.
Take AWS, for example. Suppose there’s a specific API and an API that launches an EC2 machine. Launching an EC2 machine is a task that takes considerable time. Can this time be shortened simply through code optimization?
Regardless of optimization, tasks like turning a computer on or off will still take a significant amount of time. (It would take at least 30 seconds to boot up my own computer.)
If this is handled by a synchronous API, it can be structured as follows.
Let’s take a look using the Go language:
package main
import "net/http"
func StartEc2Handler(w http.ResponseWriter, r *http.Request) {
// ...
// Code for launching an EC2 machine
// ...
w.Write([]byte(`{"result": "success"}`)) // Respond in JSON format
}Code is written without distinguishing between layers. In actual code, various layers like service and repository might exist.
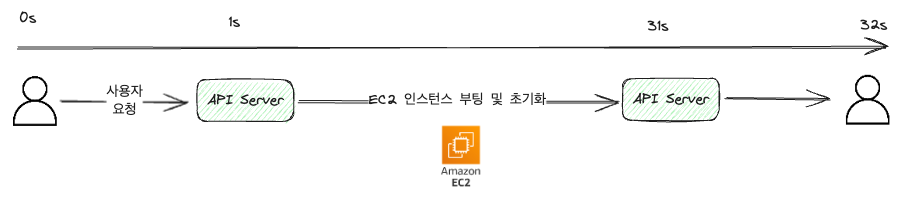
In the example above, for convenience, let’s assume that it takes 1 second for communication between the user and the server (in reality, it would be much shorter in milliseconds).
As shown in the diagram, it processes the task of launching an EC2 machine and returns the result by receiving an API request.
Synchronous methods do not respond until the request is processed, so if you leave the page or refresh, the task will be interrupted.
From the user’s perspective, they would have to stare at a loading screen for 32 seconds.
It’s nothing short of terrible.
To prevent interruption in the middle, you might have the user confirm by displaying a warning like this. But stopping the user from clicking ‘OK’ is not possible.
In my case, it took about 10 seconds per item to upload one item to three external services in a B2B service, and as it’s common to upload 100-200 items at once, making users wait over 10 minutes was very inconvenient.
Don’t use the computer for 10 minutes.-> Can you bear with it?
Solution 1: Make APIs Asynchronous
Before processing with event-driven architecture, tasks can be handled with asynchronous APIs.
Since Go is relatively easy for concurrent processing, let’s use Go as an example:
package main
import "net/http"
func StartEc2Handler(w http.ResponseWriter, r *http.Request) {
// ...
go func() {
// Code for launching an EC2 machine
// Code for creating user notification about success/failure
}()
// ...
w.WriteHeader(http.StatusAccepted) // 202 Accepted: Indicates the request has been received and the process has started
}The code above processes the code for launching an EC2 machine using a goroutine and returns a 202 Accepted to indicate the request has been received and the operation has started.
Even with such a setup, the time from request to response can be greatly reduced as shown below.
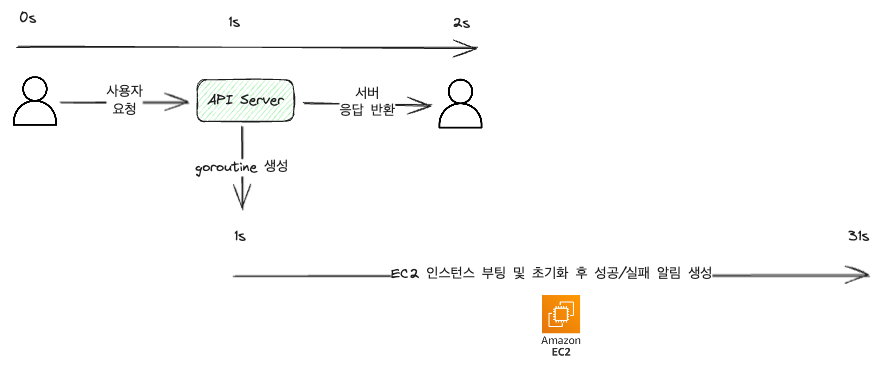
As shown above, the user’s request takes only about 2 seconds, and the response can be received very quickly. However, the code for creating notifications has been added.
This is because 202 merely indicates that the request has been received and does not guarantee that the operation has been completed.
Therefore, when responding regardless of success/failure, notifications, or status codes should be also sent to inform the client about the success/failure of the task.
Of course, there is no issue code-wise even if you don’t handle notifications. However, if you’re a developer, not ensuring that users can know the success/failure of their tasks through notifications, harms the user experience greatly. It is necessary to consider adding notifications promptly.
Did we finish it…?
Not really. There are various constraints and problems in the world.
Once you start expanding code like this, you encounter several issues, and the following three were the ones I faced:
- Asynchronous tasks generally involve a high computational load (otherwise it would be simple and problem-free to handle them synchronously). Thus, if traffic to the API increases, the server might easily go down.
- If work is interrupted due to deployments, acts of God, etc., recovery is difficult and users do not receive notifications.
- If it’s an external service API, rate limits generally exist, and if requests flood in, 429 Too Many Requests may be returned, meaning the external service might not process work properly.
Solution 2: Handling with Event-Driven Architecture
Event-driven architecture, as the name suggests, refers to an architecture that processes tasks based on events.
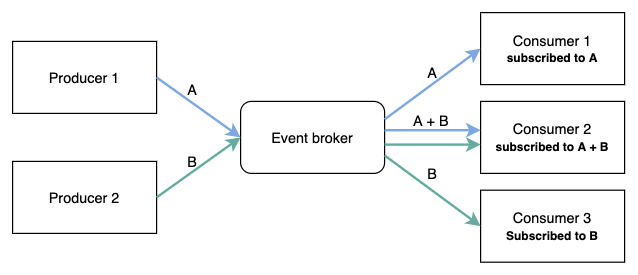
There is an Event Broker in the middle, and tasks are processed by having a Producer publish events and a Consumer subscribe to events.
Event Brokers include Kafka, RabbitMQ, AWS SNS, and so on, and Producers and Consumers exchange events through them.
Practically, the Consumer handles tasks (such as launching an EC2 machine), and the Producer publishes an event when a request is received, after which the API returns a 202 Accepted.
Let’s review the code.
In the example below, events are published using RabbitMQ and processed in a subscription manner.
package main
import (
"net/http"
amqp "github.com/rabbitmq/amqp091-go"
)
func PublishStartEc2EventHandler(w http.ResponseWriter, r *http.Request) {
// Connecting to RabbitMQ and getting a channel
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
w.Write([]byte(`{"result": "rabbitmq connection error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
ch, err := conn.Channel()
if err != nil {
w.Write([]byte(`{"result": "rabbitmq channel error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
// Publishing an event
event, err := json.Marshal(Event{
Code: "START_EC2",
RequestID: "some_uuid",
Body: "some_body",
})
if err != nil {
w.Write([]byte(`{"result": "json marshal error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
if err = ch.PublishWithContext(
r.Context(),
"",
"aws-event-queue",
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: event,
}); err != nil {
w.Write([]byte(`{"result": "rabbitmq publish error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
w.WriteHeader(http.StatusAccepted)
}The code is somewhat lengthy. The code itself isn’t important, but the role of this API is crucial.
In this API, tasks are processed in the order of Connecting to RabbitMQ -> Creating an Event Object -> JSON Serialization -> Placing Event Object in Body and Publishing Event.
In practice, connections to the Queue are shared upon application startup and generally do not need to be established with each request, but for ease of understanding, I included it to help ease concerns about seeing
conn.Channel()pop up unexpectedly.
Consumer code is quite lengthy depending on its function, so the following diagram omits it:
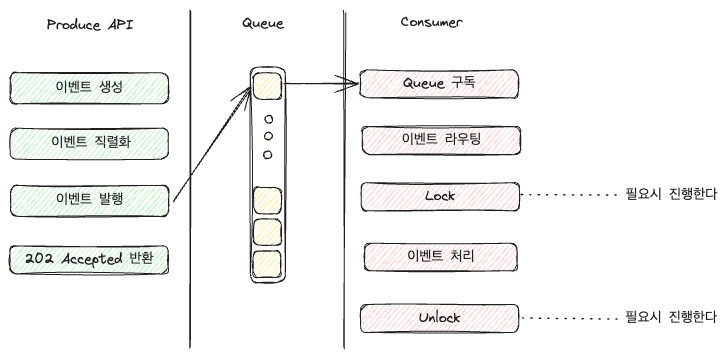
For routing, depending on the configuration, you can either create a separate Queue for each event and process it directly from the Queue, or as shown in the diagram above, handle routing within the Application.
However, as shown in the above diagram, the role of the Consumer can expand, and the burden of handling branches grows as the number of events increases.
As it scales up (more accurately, as it becomes difficult to manage), you might additionally set up a separate layer for event branching or even set up a load balancer to designate Consumers.
Why Lock?
In event-driven architecture, you can optionally lock during consumption.
A lock is a method to control concurrency for a specific resource, such as RedisLock or DB Lock.
Generally, holding a lock prevents another Consumer from processing a specific event or Queue. Once the task is completed, the lock is released, allowing another Consumer to process the said event.
I usually applied locks for the following reasons:
- In a multi-container environment, multiple Consumers inevitably exist. Without a distinct lock, it becomes uncertain whether another container is working on the said Queue, potentially consuming simultaneously by the number of Containers. I applied locks to limit the number of events processed simultaneously to this effect.
- When there are multiple Consumers, they might accidentally process the same event, so locks are applied to prevent this.
- Many external services limit the number of requests processed at once to prevent overload. My case had a very restrictive Rate Limit of about 2 per second, so I applied locks to ensure only one external service API was processed at once.
Event Chain
One advantage of event-driven architecture is that it can create an event chain to connect several events together.
For instance, the EC2 handler had the following two tasks:
- The task of launching an EC2 machine
- Creating notifications about the launched EC2 machine
When made into an event chain, it looks like this:
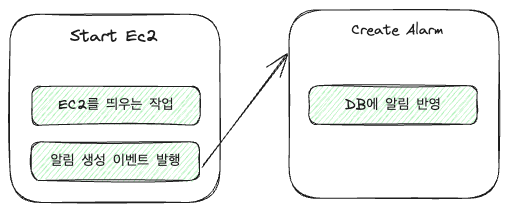
When looking at the code, it becomes even simpler; a very straightforward implementation might look as follows:
func StartEc2Event(args any) {
// Task to launch an EC2 machine
// ... Some code
// Publish a CreateAlarm event
ch.PublishWithContext(
r.Context(),
"",
"aws-event-queue",
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: event, // Roughly indicating that the task has been successful
})
}
func CreateAlarm(args any) {
// Create the notification
}Although a Consumer function, the StartEc2Event function consumes and publishes a new event, allowing for easily implementing subsequent tasks based on the event-driven model.
The more standardized the events are, the more reusable they become. In the given example, the CreateAlarm function can be used not only in the specific case but also in various other asynchronous tasks that utilize such events.
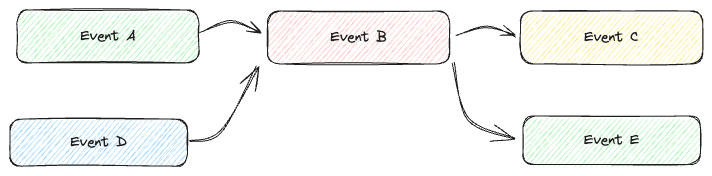
From a productivity standpoint, the significant advantage lies in not having to implement events that have already been developed.
Disadvantages
It looks straightforward when presented in these diagrams, but depending on the situation, the code can become quite complex.
The deeper the event chain gets, the harder it becomes to follow its flow, and during debugging, understanding the relationships between events can be challenging.
Therefore, it is crucial to document the relationships between events thoroughly.
In Conclusion
Event-driven architecture, when used properly, is one of the most powerful architectures available. It allows you to control the number of consumed APIs to reduce server load and increase reusability through event chains.
From a user standpoint, it’s a grateful technology enabling them to engage in other tasks while reducing the wait time from request to response. However, monitoring also requires separate configurations to bundle things into one transaction, and improper event object creation could lead to much higher complexity compared to simply handling synchronous APIs.
Therefore, I believe it’s crucial to have comprehensive discussions with team members, establish conventions in advance, and maintain those conventions well when using event-driven architecture.