Let's Crawl Using Playwright in Golang
There are various ways to collect data, and the most common method is using a technique called crawling.
Crawling, when translated literally, means to crawl. Web crawling can be thought of as collecting information by crawling the web.
Tools
Python is particularly widely used, not only because of its simplicity but also because there are many libraries specialized for crawling. Well-known tools include BeautifulSoup, Selenium, and Scrapy.
Recently, a tool called Playwright has emerged, which is generally used more for test automation than crawling, but it can also be used for crawling. Unlike BeautifulSoup that merely plays a parser role, Playwright can control browser-related actions based on a real browser, which is useful for executing JavaScript or crawling SPAs (Single Page Applications).
This tool supports various languages including Node.js, Python, and Go. This time, I intend to use Playwright with Go.
Installing Playwright
To use Playwright in Go, you must first utilize a library called playwright-go.
You can install it using the following command.
go get github.com/playwright-community/playwright-goAdditionally, you need to install the browser dependencies for executing the crawler. It can be easily installed using the command below.
go run github.com/playwright-community/playwright-go/cmd/playwright@latest install --with-depsImplementing Crawling Using Playwright
Now, let’s conduct the actual crawling.
I will simply crawl this current blog.
As the code is lengthy, it is explained step by step.
1. Playwright Setup
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
defer pw.Stop()
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Headless: playwright.Bool(true), // Set to false to show the browser
})
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
defer browser.Close()
page, err := browser.NewPage(playwright.BrowserNewPageOptions{
UserAgent: playwright.String("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"),
})
if err != nil {
log.Fatalf("could not create page: %v", err)
}
defer page.Close()First, the playwright.Run() function creates a Playwright instance, which is used for running the browser and creating pages.
The playwright.BrowserType.Launch() function runs the browser. It takes a playwright.BrowserTypeLaunchOptions struct as an argument where setting the Headless option to true ensures the browser runs without being visible.
Various other options can be specified as well. For detailed information, refer to the official documentation. However, explanations are based on JavaScript, so when using in Go, it might require checking the function annotations directly.
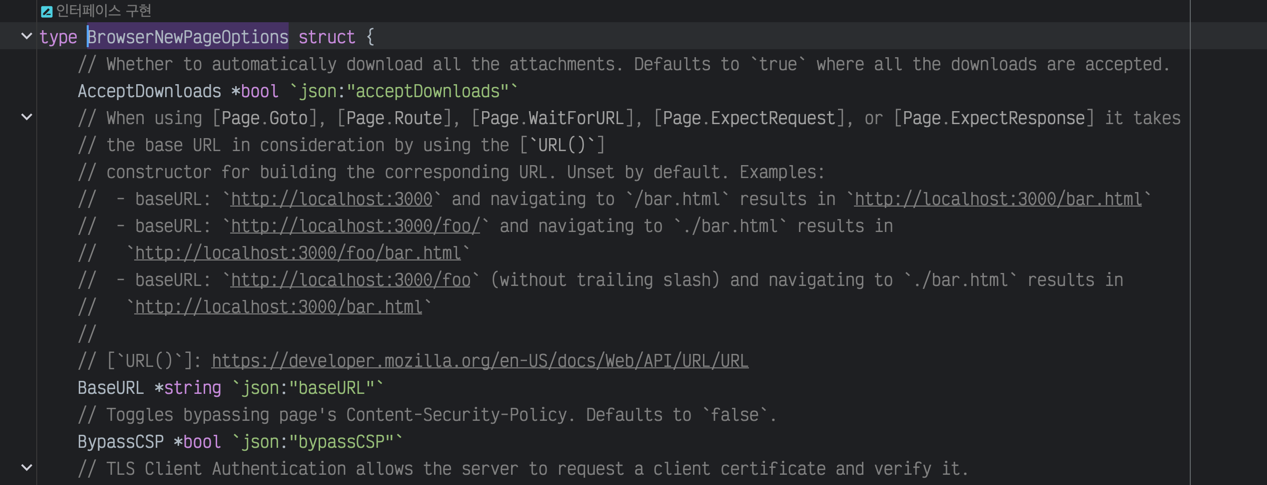
Refer to the browser option annotations
The browser.NewPage() function creates a new page. It takes a playwright.BrowserNewPageOptions struct as an argument, where the UserAgent option sets the UserAgent of the browser.
Generally, many sites check the UserAgent. This is particularly relevant for cases where bots are blocked or certain JavaScripts are prevented from execution.
The author set the UserAgent to Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3 to make it seem like the access is coming from a real browser.
2. Crawling
Now let’s dive into the crawling process.
I will explain the functions you will frequently use one by one.
Goto: Navigate to a Page by URL
response, err := page.Goto("https://yangtaeyoung.github.io/blog", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateLoad,
})
if err != nil {
log.Fatalf("could not goto: %v", err)
}Goto is a function derived from the page, which navigates to the specified page. It takes a playwright.PageGotoOptions struct as an argument, with the WaitUntil option specifying to wait until the page has been fully loaded.
Options include playwright.WaitUntilStateLoad, playwright.WaitUntilStateNetworkidle, and playwright.WaitUntilStateDomcontentLoaded, among others.
The author frequently used playwright.WaitUntilStateNetworkidle, an option that waits until the network no longer requests anything, especially useful for client-side rendered pages that might not be fully loaded with a simple Load.
The example uses playwright.WaitUntilStateLoad since it’s a static page without needing to wait for JavaScript execution specifically.
Locator: Find Elements
Now it comes to the core of crawling — finding elements. In Playwright, you can find elements by using the Locator function with various methods.
First, let’s aim to extract all category titles that include a star symbol from the category page of my blog.
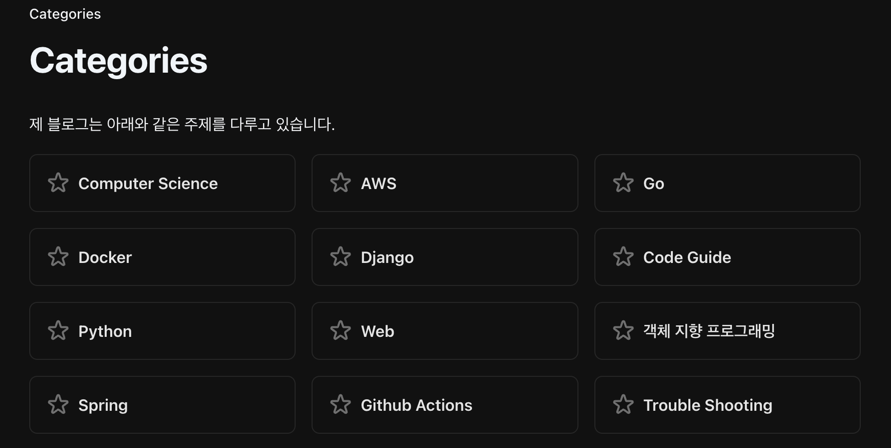
First, find a desired element, right-click and select the inspect button.
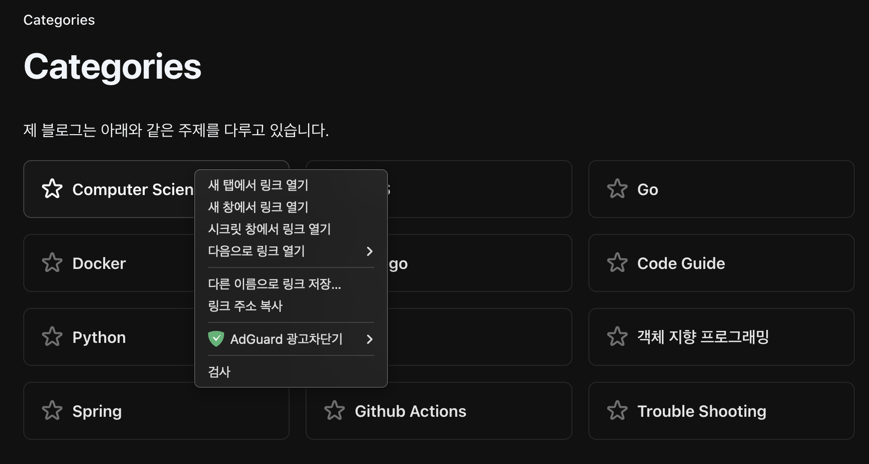
Now the source code appears, and you’ll need to determine the rules for each category.
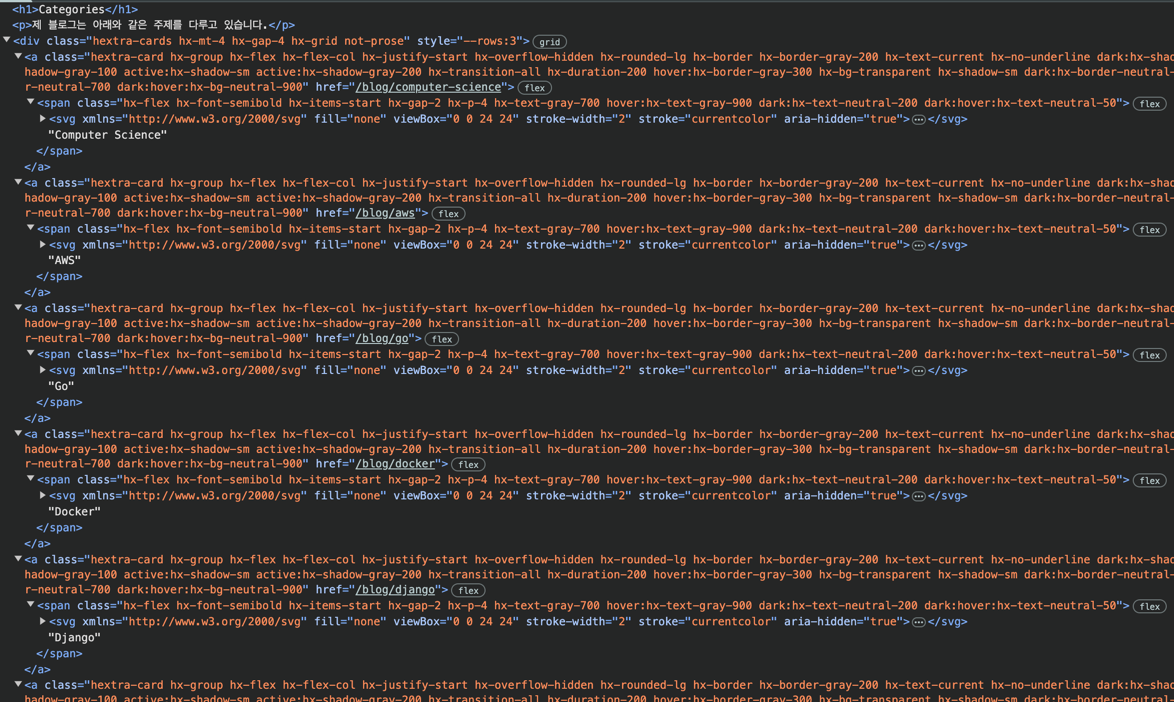
The titles are all contained within span tags under a tags, which are under div tags.
However, obviously, there are many such cases, so we need to identify more specific rules.
Checking the classes, div tags have hextra-cards and a tags have hextra-card.
Upon inspecting other elements, no other rules appeared to be visible.
Thus, what needs to be located is:
`span tag under `a` tag with class `hextra-card` under `div` tag with class `hextra-cards``Now let’s translate this into code.
titleElements, err := page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span").All()
if err != nil {
log.Fatalf("could not find elements: %v", err)
}
}Using page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span"), Locator allows chaining. This means finding div.hextra-cards, then a.hextra-card within it, and finally span within the latter.
Though a single locator can be used, I wanted the entire category, so I used All() to retrieve all matching Locators and stored them in titleElements.
Let’s extract the titles, noting there’s an issue with them.

There’s a tiny svg tag incorporated to represent the stars.
Simple use of InnerHTML will include the svg tag, making additional efforts necessary to extract titles alone by removing tags.
Fortunately, Playwright provides an InnerText() function to get the internal text alone. Using it to extract just title results in:
titles := make([]string, len(titleElements))
for _, titleElement := range titleElements {
var title string
title, err = titleElement.InnerText()
if err != nil {
log.Fatalf("could not get inner text: %v", err)
}
titles = append(titles, title)
}
slog.Info("Success Crawled Titles", "titles", titles)We then get the code below:
2025/02/14 02:00:13 INFO Success Crawled Titles titles="[ Computer Science AWS Go Docker Django Code Guide Python Web Object-Oriented Programming Spring Github Actions Trouble Shooting]"Impressively, category titles are well crawled.
Other well-used functions are as follows:
| Function Name | Description |
|---|---|
GetAttribute() | Retrieves the attribute of an element. For example, to find the href attribute within an A tag, use this function. |
Click() | Clicks on an element. If a link is a JavaScript and the URL cannot be discerned, the crawler can be instructed to click. |
InnerHTML() | Retrieves the internal HTML of an element. |
IsVisible() | Checks if an element is visible. If the element is absent or the display property is none, it returns true. |
IsEnabled() | Confirms if an element is enabled. |
Count() | Returns the count of elements. |
Based on simple crawling tasks, I often used InnerText, InnerHTML, and GetAttribute. Many more functions are available; however, surfing the code briefly reveals easily understandable explanations with familiar function names.
Nowadays, GPT provides great explanations.
A picture showing the list of functions appearing through auto-completion, highlighting the diverse functions available.
Full Code
Here’s the full code used to scrape my categories. I hope running this code massively increases the visitor count to my blog 🤣
package main
import (
"log"
"log/slog"
"github.com/playwright-community/playwright-go"
)
func main() {
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
defer pw.Stop()
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Headless: playwright.Bool(true), // Set to false to show the browser
})
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
defer browser.Close()
page, err := browser.NewPage(playwright.BrowserNewPageOptions{
UserAgent: playwright.String("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"),
BypassCSP: playwright.Bool(true),
})
if err != nil {
log.Fatalf("could not create page: %v", err)
}
defer page.Close()
if _, err := page.Goto("https://yangtaeyoung.github.io/blog", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateNetworkidle,
}); err != nil {
log.Fatalf("could not goto: %v", err)
}
titleElements, err := page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span").All()
if err != nil {
log.Fatalf("could not find title elements: %v", err)
}
titles := make([]string, len(titleElements))
for _, titleElement := range titleElements {
var title string
title, err = titleElement.InnerText()
if err != nil {
log.Fatalf("could not get inner text: %v", err)
}
titleElement.
titles = append(titles, title)
}
slog.Info("Success Crawled Titles", "titles", titles)
}In Conclusion
While Playwright seems to be used extensively for test automation, there’s not much usage in the Golang side (especially appears there’s very little documentation available in Korea).
Crawling in Go has become quite flexible, and while data collection is challenging at the start of a project, utilizing such tools makes collecting data for big data analysis or AI easier.