Ereignisbasierte Architektur (Event Driven Architecture) aus Sicht eines API-Servers verstehen
Manchmal kommt es bei der Entwicklung vor, dass die Antwortzeiten eines API langsam sind. In solchen Fällen kann man versuchen, die Antwortzeiten zu verbessern, indem man den Code optimiert oder Caching einführt.
Natürlich sind diese Methoden, wenn sie funktionieren, nützlich und die besten, aber manchmal gibt es Arbeiten, die zwangsweise viel Zeit in Anspruch nehmen.
Nehmen wir AWS als Beispiel: Angenommen, es gibt ein bestimmtes API und ein API zum Starten einer EC2-Maschine. Das Starten einer EC2-Maschine ist eine Aufgabe, die eine Weile dauert. Kann man diese Zeit nur durch Code-Optimierung verkürzen?
Auch wenn man den Computer ein- und ausschaltet, wird es eine Weile dauern, egal wie sehr man optimiert. (Zum Beispiel braucht mein Computer mindestens 30 Sekunden zum Booten.)
Wenn man dies mit einem synchronen API behandelt, könnte es wie folgt aussehen.
Schauen wir uns das mal mit der Programmiersprache Go an.
package main
import "net/http"
func StartEc2Handler(w http.ResponseWriter, r *http.Request) {
// ...
// Code zum Starten der EC2-Maschine
// ...
w.Write([]byte(`{"result": "success"}`)) // Antwort im JSON-Format
}Der Code wurde ohne Unterscheidung der Schichten geschrieben. In realem Code gibt es verschiedene Schichten wie Service, Repository usw.
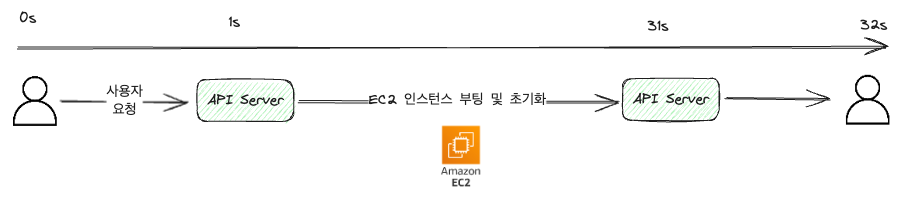
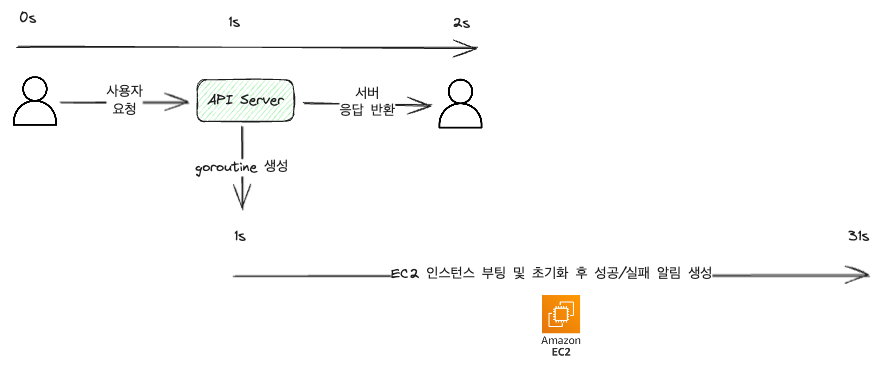
Im obigen Beispiel nehmen wir zur Vereinfachung an, dass die Kommunikation zwischen Benutzer und Server eine Sekunde dauert. (In Wirklichkeit würde es viel kürzer im ms-Bereich sein.)
Wie das Bild zeigt, wird die Anfrage empfangen, die Aufgabe zum Starten der EC2-Maschine bearbeitet und dann das Ergebnis zurückgegeben.
Da der synchrone Ansatz erst antwortet, wenn die Anfrage bearbeitet ist, wird die Arbeit unterbrochen, wenn der Benutzer die Seite verlässt oder aktualisiert.
Aus Sicht des Benutzers muss man 32 Sekunden lang einen Ladebildschirm ansehen.
Das wäre fürchterlich.
Um eine Unterbrechung zu vermeiden, gibt es auch eine Umsetzung, die eine Warnung ausgibt. Aber man kann nicht verhindern, dass der Benutzer auf “Bestätigen” klickt.
In meinem Fall hat es bei einem B2B-Dienst ungefähr 10 Sekunden gedauert, ein einzelnes Produkt zu drei externen Diensten hochzuladen. Normalerweise werde zwischen 100 und 200 Produkte hochgeladen, was bedeutete, dass Benutzer mehr als 10 Minuten warten mussten, was sehr unbequem war.
Benutzen Sie Ihren Computer nicht für 10 Minuten.-> Können Sie das ertragen?
Lösung 1: API asynchron machen
Bevor man eine eventbasierte Lösung in Betracht zieht, kann man die API asynchron gestalten.
Da Go es einfach macht, gleichzeitige Operationen durchzuführen, nehmen wir Go als Beispiel.
package main
import "net/http"
func StartEc2Handler(w http.ResponseWriter, r *http.Request) {
// ...
go func() {
// Code zum Starten der EC2-Maschine
// Code zum Erstellen von Benutzerbenachrichtigungen über Erfolg/Misserfolg
}()
// ...
w.WriteHeader(http.StatusAccepted) // 202 Accepted: signalisiert, dass die Anfrage empfangen wurde und eine Bearbeitung begonnen hat
}Der obige Code behandelt das Starten der EC2-Maschine in einer Goroutine und gibt 202 Accepted zurück, um anzuzeigen, dass die Anfrage empfangen wurde und die Bearbeitung begonnen hat.
Bereits so kann man die Zeit, die vom Empfang der Anfrage bis zur Antwort vergeht, erheblich verkürzen.
Wie man sieht, hält sich die Anfrage des Benutzers nur etwa 2 Sekunden und man erhält sehr schnell eine Antwort. Es ist jedoch zusätzlicher Code zum Erstellen von Benachrichtigungen hinzugekommen.
Das liegt daran, dass 202 nur bescheinigt, dass die Anfrage empfangen wurde, aber nicht, dass die Bearbeitung abgeschlossen ist.
In so einem Fall, wo man unabhängig vom Erfolg/Misserfolg antwortet, sollte man sicherstellen, dass es eine Benachrichtigung oder Statuscodes gibt, um den Erfolg/Misserfolg der Arbeit dem Client mitzuteilen.
Natürlich ist dies nicht zwingend notwendig, aber für Nutzererfahrungen ist es wichtig. Entwicklern sollte bewusst sein, dass Benutzer nicht wissen, ob eine Arbeit erfolgreich oder fehlgeschlagen ist, was die Nutzererfahrung stark beeinträchtigen könnte, und sie sollten darüber nachdenken, Benachrichtigungen so schnell wie möglich hinzuzufügen.
Ist es erledigt…?
Nein. In der Welt gibt es verschiedene Einschränkungen und Probleme.
Wenn man seinen Code für folgende Fälle erweitert, kann man auf diverse Probleme stoßen, und die drei, die mir begegnet sind, waren die folgenden:
- Vertrauen in eine asynchrone Aufgabe bedeutet oft, dass sie rechenintensiv ist (anderenfalls könnte man sie synchron abarbeiten, was einfacher wäre und kein Problem darstellt). Deshalb kann es leicht zu Serverausfällen kommen, wenn der Traffic zu diesem API stark zunimmt.
- Wenn die Arbeit aufgrund von Deployment, Naturkatastrophen usw. unterbrochen wird, ist die Wiederherstellung schwierig, und der Benutzer erhält keine Benachrichtigung.
- Bei externen Dienst-APIs gibt es oft eine Rate Limitierung, und wenn Anfragen gehäuft auftreten, könnte der externe Dienst eine 429 Too Many Requests zurückgeben und die Arbeit möglicherweise nicht korrekt verarbeiten.
Lösung 2: Verarbeitung mit ereignisbasierter Architektur (Event Driven Architecture)
Die ereignisbasierte Architektur bedeutet, dass Aufgaben auf Basis von Ereignissen abgearbeitet werden.
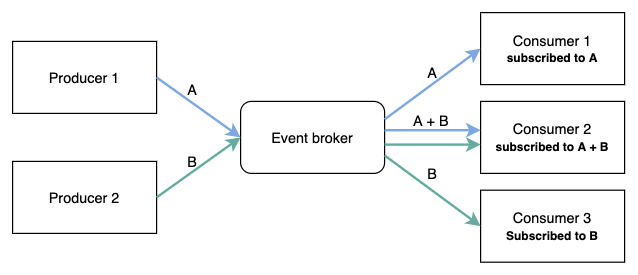
In der Mitte befindet sich ein Event Broker; Produzenten veröffentlichen Ereignisse, und Konsumenten abonnieren diese, um Aufgaben zu bearbeiten.
Typische Event Broker sind Kafka, RabbitMQ, AWS SNS usw. über die Produzenten und Konsumenten Ereignisse senden und empfangen.
Die Bearbeitung der eigentlichen Aufgaben (wie das Starten einer EC2-Maschine) übernimmt der Konsument, während der Produzent das Ereignis nach Empfang der Anfrage herausgibt und das API eine 202 Accepted zurückgibt.
Schauen wir uns das einmal im Code an.
Im folgenden Beispiel verwenden wir RabbitMQ, um Ereignisse zu veröffentlichen und zu abonnieren.
package main
import (
"net/http"
amqp "github.com/rabbitmq/amqp091-go"
)
func PublishStartEc2EventHandler(w http.ResponseWriter, r *http.Request) {
// rabbitmq Verbindung und Channel erhalten
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
w.Write([]byte(`{"result": "rabbitmq connection error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
ch, err := conn.Channel()
if err != nil {
w.Write([]byte(`{"result": "rabbitmq channel error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
// Ereignisse veröffentlichen
event, err := json.Marshal(Event{
Code: "START_EC2",
RequestID: "some_uuid",
Body: "some_body",
})
if err != nil {
w.Write([]byte(`{"result": "json marshal error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
if err = ch.PublishWithContext(
r.Context(),
"",
"aws-event-queue",
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: event,
}); err != nil {
w.Write([]byte(`{"result": "rabbitmq publish error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
w.WriteHeader(http.StatusAccepted)
}Der Code ist etwas lang. Der Code selbst ist jedoch nicht das entscheidende, sondern die Rolle des APIs ist wichtig.
Das API verbindet sich mit RabbitMQ -> erstellt ein Ereignisobjekt -> serialisiert es als JSON -> gibt das Ereignisobjekt als Inhalt an das Ereignis heraus.
Tatsächlich teilt man die Verbindung zur Warteschlange in der Regel, um sie bei der Anwendungsausführung zu nutzen und müsste daher normalerweise nicht bei jedem Aufruf ein
conn.Channel()sehen, aber es ist im Code enthalten, um das Verständnis zu erleichtern.
Der Consumer-Code kann je nach Funktionalität sehr lang sein, aber das lasse ich hier aus und zeige stattdessen eine Abbildung.
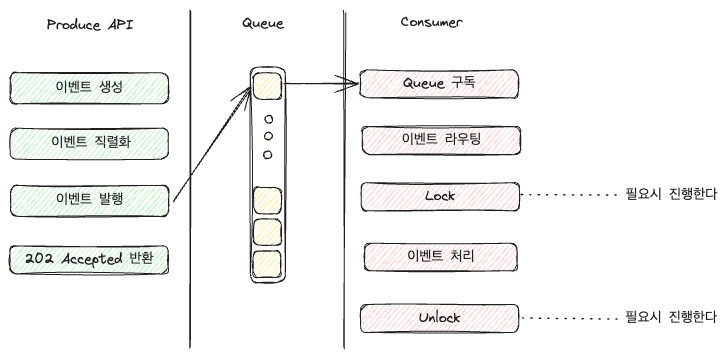
Je nach Konfiguration kann man für jedes einzelne Ereignis eine eigene Warteschlange erstellen und diese direkt verarbeiten oder, wie im Bild, die Anwendung die Ereignisse entgegennehmen und weiterleiten lassen.
Einfach ausgedrückt erhöht sich die Rolle des Consumers, sodass die Last, die durch Verzweigungen entsteht, größer wird, je mehr Ereignisse es gibt.
Bei größerem Umfang (genauer gesagt, wenn die Verwaltung schwer wird), könnte man eine separate Ebene zur Verzweigungsbearbeitung der Ereignisse einführen oder einen Load Balancer, um den Consumer zu spezifizieren.
Warum sperren?
Bei der ereignisbasierten Architektur kann man wählen, ob man beim Konsumieren sperrt.
Sperrung (Lock) erfolgt durch RedisLock, DB Lock, usw., um die Gleichzeitigkeit für bestimmte Ressourcen zu steuern.
Generell kann man durch Sperren verhindern, dass andere Consumer bestimmte Ereignisse oder Warteschlangen gleichzeitig verarbeiten. Und wenn die Arbeit beendet ist, wird die Sperre aufgehoben, damit andere Consumer das Ereignis bearbeiten können.
Aus den folgenden Gründen habe ich oft gesperrt:
- In einer Multi-Container-Umgebung gibt es sicherlich mehrere Consumer. Wenn es keine separate Sperre gibt, wissen andere Container möglicherweise nicht, dass eine Arbeit mit der Warteschlange im Gange ist, weshalb manchmal so viele gleichzeitig verarbeitet werden, wie es Container gibt. Um die Anzahl der Ereignisse, die gleichzeitig verarbeitet werden, zu begrenzen, habe ich gesperrt.
- Wenn es mehrere Consumer gibt, kann es passieren, dass dasselbe Ereignis mehrfach bearbeitet wird, weshalb ich aus diesem Grund gesperrt habe.
- Da externe Dienste in der Regel ein Limit für gleichzeitige Anfragen zur Lastvermeidung haben und mein Limit bei 2 Anfragen pro Sekunde sehr niedrig war, habe ich aus diesem Grund gesperrt, um die gleichzeitige Verarbeitung externer Dienst-APIs zu beschränken.
Ereigniskette
Ein Vorteil der ereignisbasierten Architektur ist, dass man durch eine Ereigniskette mehrere Ereignisse verbinden kann.
Zum Beispiel gab es beim EC2-Handler zwei Aufgaben:
- Das Starten der EC2-Maschine
- Erstellen einer Benachrichtigung über die gestartete EC2-Maschine
Das lässt sich in einer Ereigniskette wie folgt abbilden:
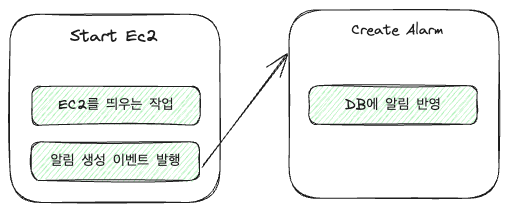
Einfache Codes sehen folgendermaßen aus:
func StartEc2Event(args any) {
// Arbeit zum Starten der EC2-Maschine
// ... Etwas Code
// ErstelleAlarm-Ereignis veröffentlichen
ch.PublishWithContext(
r.Context(),
"",
"aws-event-queue",
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: event, // Grob gesagt, dass diese Aufgabe erfolgreich war
})
}
func CreateAlarm(args any) {
// Alarm erstellen
}Obwohl es eine Verbraucherfunktion ist, verbraucht StartEc2Event ein Ereignis und veröffentlicht ein neues. Auf diese Weise kann man in einer Ereignisbasis einfach Folgenereignisse umsetzen.
Je besser die Ereignisse standardisiert sind, desto höher ist die Wiederverwendbarkeit. Das in den Beispielen verwendete CreateAlarm könnte in verschiedenen asynchronen Aufgaben verwendet werden, nicht nur in diesem Fall.
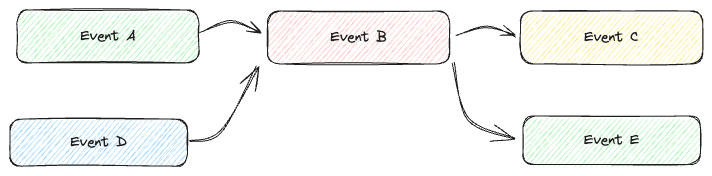
Aus Sicht der Produktivität ist es ein großer Vorteil, dass Sie vorher implementierte Ereignisse nicht neu implementieren müssen.
Nachteile
Obwohl es auf dem Diagramm leicht aussieht, kann es im Code je nach Fall sehr komplex werden.
Je tiefer eine Ereigniskette wird, desto schwerer ist es, den Empfang zu verfolgen; auch beim Debuggen kann es schwierig sein, die Beziehungen zwischen den Ereignissen zu verstehen.
Deshalb müssen die Beziehungen der Ereignisse gut dokumentiert werden.
Fazit
Ereignisbasierte Architektur ist eine der mächtigen Architekturen, wenn sie richtig verwendet wird. Man kann die Anzahl der APIs, die konsumiert werden, anpassen, um die Serverlast zu reduzieren, und die Wiederverwendbarkeit durch Ereignisketten erhöhen.
Für Benutzer ist dies auch eine nützliche Technologie, da sie die Wartezeit auf eine Antwort während einer Anfrage reduziert und auch andere Arbeiten ermöglicht.
Man muss allerdings auch für Dinge wie Monitoring einige Einstellungen vornehmen, um sie in einem einzigen Transaktionsfluss zusammenzufassen. Fehlerhafte Ereignisobjekte könnten die Komplexität im Vergleich zu einer einfachen synchronen API stark erhöhen.
Deshalb denke ich, dass es wichtig ist, bei der Verwendung von ereignisbasierten Architekturen im Vorfeld ausführlich mit dem Team zu diskutieren, Konventionen festzulegen und diese gut zu pflegen und aufrechtzuerhalten.