Redis Cache in Spring Boot anwenden
Obwohl es schon eine Weile her ist, habe ich einmal API-Lasttests mit einem Tool namens Locust durchgeführt. Um die Verzögerung einer bestimmten API-Antwort zu lösen, habe ich Redis Cache angewendet und möchte diese Erfahrung teilen.
Was ist ein Cache?
Ein Cache ist ein Speicherbereich, der Daten oder Werte vorab speichert, damit man schneller darauf zugreifen kann.
Grundsätzlich wird zwar auf RDBs, die auf der Festplatte gespeichert sind, zugegriffen, aber im Vergleich zu Redis, das im Speicher gespeichert ist, kann man Daten mit hoher Geschwindigkeit abrufen.
Natürlich kann der detaillierte Ablauf je nach Cache-Strategie unterschiedlich sein, aber wenn man von der allgemeinen Cache-Strategie Look-Aside Cache ausgeht, wird er wie folgt erklärt.
Cache Hit
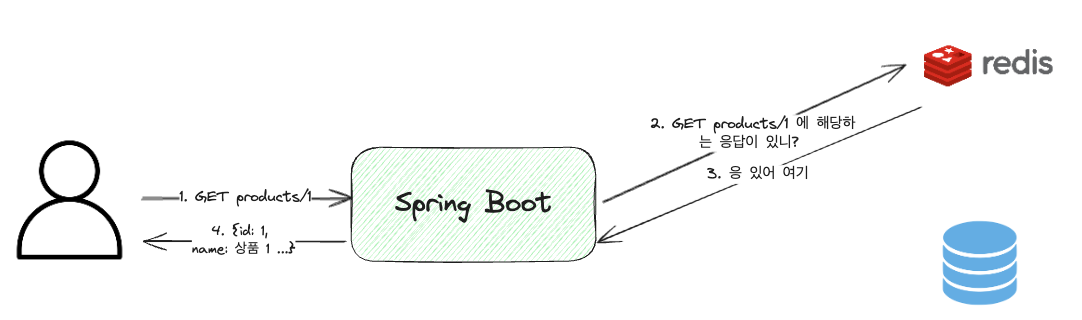
Ein Cache-Hit bezeichnet den Fall, in dem Daten im Cache vorhanden sind. In diesem Fall werden die im Cache gespeicherten Daten abgerufen und verwendet, wodurch die für den Abruf der Daten benötigte Zeit sehr kurz ist.
Cache Miss
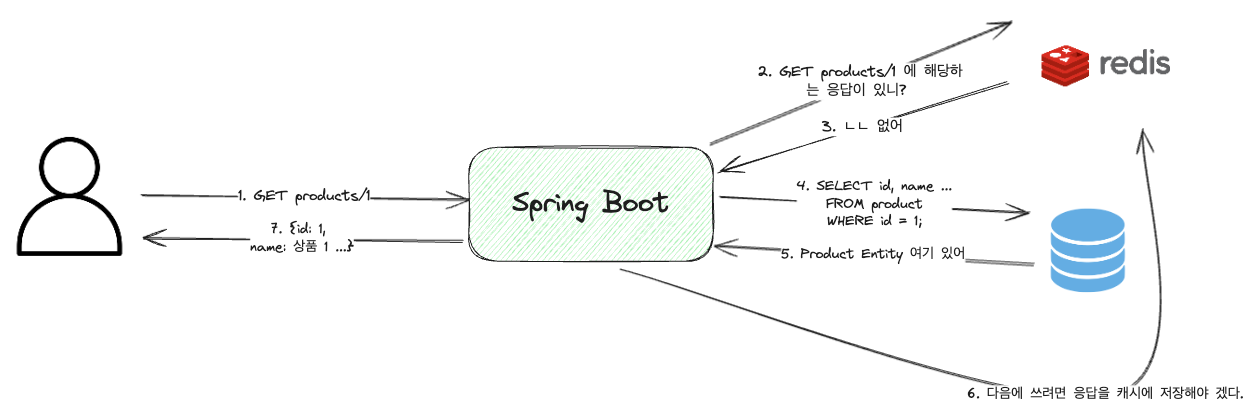
Ein Cache-Miss bezeichnet den Fall, in dem Daten im Cache nicht vorhanden sind. In diesem Fall müssen die Daten aus der Datenbank oder einem anderen Speicher abgerufen werden, wobei dann der Prozess durchlaufen wird, die Daten in Redis zu prüfen, die Daten aus der Datenbank abzurufen und die Antwort erneut in Redis zu speichern.
Daher kann es in diesem Fall langsamer sein als ohne Cache.
Warum Redis als Cache verwenden?
Redis steht für Remote Dictionary Server und ist eine Open-Source-Datenbank mit einer speicherbasierten Key-Value-Struktur.
Man kann es einfach als Datenbank betrachten.
Auch wenn man normalerweise Daten aus einer RDB abruft, gibt es kein großes Problem, wenn die Indizierung gut durchgeführt wird, um Daten schnell abzurufen.
Jedoch verlangen Abfrageergebnisse, Paging etc., die auf Suchabfragen basieren, in der Regel eine große Berechnungsmenge, weshalb es effizient ist, solche Ergebnismengen im Cache zu speichern und wiederzuverwenden.
Redis Cache in Spring Boot anwenden
1. Abhängigkeit hinzufügen
Zuerst müssen wir eine Abhängigkeit für die Nutzung von Redis hinzufügen.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'2. Redis-Konfiguration hinzufügen
Die Konfiguration für die Verbindung zu Redis muss hinzugefügt werden.
@RequiredArgsConstructor
@Configuration
@EnableRedisRepositories
public class RedisConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(host, port);
}
@Bean
public RedisTemplate<String, Object> redisTemplate() {
var redisTemplate = new RedisTemplate<String, Object>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(redisConnectionFactory());
return redisTemplate;
}
}Zuerst ist redisConnectionFactory() die Factory, die die Verbindung zu Redis herstellt, wobei LettuceConnectionFactory verwendet wird.
Unter den Java-Clients, die häufig für die Verbindung zu Redis verwendet werden, sind Jedis und Lettuce die größeren Alternativen, wobei Lettuce wegen der Unterstützung von asynchroner Verarbeitung und der Nutzung von Netty als schneller gilt.
redisTemplate() ist die Vorlage zum Speichern und Abrufen von Daten in Redis. Die Serializer für Key und Value werden durch setKeySerializer() und setValueSerializer() festgelegt. Hier wird einfach StringRedisSerializer verwendet.
3. Cache-Konfiguration hinzufügen
@Configuration
@EnableCaching
public class CacheConfig {
private Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer() {
var objectMapper = new ObjectMapper();
objectMapper.registerModule(new JavaTimeModule());
objectMapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
objectMapper.enable(MapperFeature.ACCEPT_CASE_INSENSITIVE_ENUMS);
objectMapper.configure(
JsonReadFeature.ALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER.mappedFeature(), true);
objectMapper.activateDefaultTyping(
objectMapper.getPolymorphicTypeValidator(),
ObjectMapper.DefaultTyping.EVERYTHING,
JsonTypeInfo.As.WRAPPER_OBJECT
);
objectMapper.setSerializationInclusion(JsonInclude.Include.NON_NULL);
return new Jackson2JsonRedisSerializer<>(objectMapper, Object.class);
}
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheConfiguration defaultCacheConfig =
RedisCacheConfiguration.defaultCacheConfig()
// TTL Konfiguration (z.B.: 60 Sekunden)
.entryTtl(Duration.ofSeconds(60))
// Null-Wert-Caching verhindern
.disableCachingNullValues()
// Schlüssel-Serialisierung
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new StringRedisSerializer()))
// Wert-Serialisierung
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
jackson2JsonRedisSerializer()));
return RedisCacheManager
.builder(connectionFactory)
.cacheDefaults(defaultCacheConfig)
.build();
}
}Es wurde die CacheConfig-Klasse erstellt, um die Cache-Konfiguration festzulegen.
- Die Methode
jackson2JsonRedisSerializer()erstellt einenJackson2JsonRedisSerializerund legt die JSON-Serialisierung mit einem ObjectMapper fest. DurchregisterModule()wurde dasJavaTimeModuleregistriert, um die Java 8 Date/Time API ohne Probleme zu serialisieren/deserialisieren. Andernfalls wird bei der Serialisierung von Objekten aus demjava.time-Paket ein Fehler wie folgt auftreten:com.fasterxml.jackson.databind.exc.InvalidDefinitionException: No serializer found for class java.time.LocalDateTime and no properties discovered to create BeanSerializer (to avoid exception, disable SerializationFeature.FAIL_ON_EMPTY_BEANS)disable()deaktiviertWRITE_DATES_AS_TIMESTAMPS, sodass Date/Time-Objekte nicht als Timestamps serialisiert werden.enable()aktiviertACCEPT_CASE_INSENSITIVE_ENUMS, um Groß-/Kleinschreibung bei Enums zu ignorieren.configure()aktiviertALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER, um es zu erlauben, Backslashes in JSON-Zeichenfolgen zu escapen.activateDefaultTyping()aktiviertEVERYTHING, um Typinformationen aller Objekte zu serialisieren.- Dadurch wird beim Speichern von JSON ein
@class-Feld hinzugefügt, das Typinformationen zu allen Objekten speichert. Dies hilft beim Deserialisieren auf die Typinformationen zuzugreifen.
Bei dieser Methode kann es allerdings zu Problemen kommen, dass der Typ nicht erkannt wird, wenn er verschoben wird, daher sollte man Cache-Bereinigungsmethoden wie Cache-Invalidierung bei der Veröffentlichung berücksichtigen.
- Dadurch wird beim Speichern von JSON ein
setSerializationInclusion()wird aufNON_NULLgesetzt, um zu verhindern, dass null-Werte Felder serialisiert werden.
- Die Methode
cacheManager()erstellt einenRedisCacheManager, der für die detaillierte Einstellungen der Speicherung und des Abrufens von Cache-Daten in Redis verantwortlich ist.- Über
defaultCacheConfig()holt man die Standard-Cache-Konfiguration und durchentryTtl()wird die TTL des Caches festgelegt. Hier ist es auf 60 Sekunden gesetzt. (Wenn es zu lange eingestellt wird, kann es zu Inkonsistenzen zwischen Cache und echten Daten kommen, daher sollten Cachezeit und Cache-Update-Strategie sorgfältig abgewogen werden.)
- Über
4. Verwendung von Cacheable, CacheEvict, CachePut
@Cacheable
Das @Cacheable-Annotation speichert das Ergebnis einer Methode im Cache und gibt bei einem Aufruf mit den gleichen Parametern das gecachte Ergebnis zurück.
@RestController
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/products/{id}")
@Cacheable(value = "product", key = "#id")
public Product getProduct(@PathVariable Long id) {
return productService.getProduct(id);
}
}Das @Cacheable-Annotation wird der Methode hinzugefügt, die den Cache verwenden soll, und legt durch value den Cachename und durch key den Cache-Schlüssel fest.
@CacheEvict
Das @CacheEvict-Annotation löscht die Daten aus dem Cache, wenn die Methode aufgerufen wird.
Für das Abrufen von Listen kann man eine Strategie festlegen, um den Cache zu löschen, wenn Erstellungen, Bearbeitungen oder Löschungen auftreten, da es schwierig sein kann zu erkennen, welche Daten die Listenabfrage beeinflussen.
Auch bei einem Einzelabruf-API wäre es sicherer, den Cache zu löschen, wenn Daten mit einer bestimmten ID-Wert geändert werden.
@RestController
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/products/{id}")
@Cacheable(value = "product", key = "#id")
public Product getProduct(@PathVariable Long id) {
return productService.getProduct(id);
}
@PostMapping("/products")
@CacheEvict(value = "product", allEntries = true) # Wenn es kein API zum Abrufen von Listen gibt, ist es nicht notwendig, dies festzulegen
public Product createProduct(@RequestBody Product product) {
return productService.createProduct(product);
}
}Das @CacheEvict-Annotation wird der Methode hinzugefügt, bei der der Cache gelöscht werden soll, und legt durch value den Cachename und durch allEntries fest, ob alle Caches gelöscht werden sollen.
- Wenn es nur Einzelabrufe gibt, kann man durch
keygezielt den Cache für einen bestimmten Schlüssel löschen.
@CachePut
Das @CachePut-Annotation speichert das Ergebnis der Methode im Cache und gibt das gecachte Ergebnis zurück, ohne die Methode aufzurufen.
@RestController
public class ProductController {
@Autowired
private ProductService productService;
@GetMapping("/products/{id}")
@Cacheable(value = "product", key = "#id")
public Product getProduct(@PathVariable Long id) {
return productService.getProduct(id);
}
@GetMapping("/products")
@Cacheable(value = "product")
public ListProductsResponse listProducts() {
return productService.listProducts();
}
@PostMapping("/products")
@CacheEvict(value = "product", allEntries = true) # Wenn es kein API zum Abrufen von Listen gibt, ist es nicht notwendig, dies festzulegen. Wenn es einen Einzelabruf gibt, wäre die Verwendung von CachePut eine Möglichkeit.
public Product createProduct(@RequestBody Product product) {
return productService.createProduct(product);
}
@PutMapping("/products/{id}")
@CachePut(value = "product", key = "#id")
public Product updateProduct(@PathVariable Long id, @RequestBody Product product) {
return productService.updateProduct(id, product);
}
}Das @CachePut-Annotation wird der Methode hinzugefügt, bei der der Cache aktualisiert werden soll, und legt durch value den Cachename und durch key den Cache-Schlüssel fest.
Sollte man unbedingt einen Cache verwenden?
Je mehr Daten vorhanden sind, je öfter die gleiche Antwort mehrfach verwendet wird und je komplexer der Rechenaufwand ist, desto vorteilhafter ist es, einen Cache zu verwenden.
Allgemein werden statische Daten wie Bilder und Videos selten geändert, daher wird in den meisten Browsern und CDNs ebenfalls Cache verwendet.
In Fällen, wo Daten jedoch häufig geändert werden, sollte man keinen Cache verwenden. Für Daten, bei denen Echtzeit wichtiger ist (z.B. Kontostand, Lieferinformationen), wäre es vorteilhafter, keinen Cache zu verwenden. (Da es schwieriger sein kann, Dateninkonsistenzen zu lösen.)
Letztendlich sollten bei der Entscheidung, ob ein Cache verwendet werden soll, die Eigenschaften der Daten, das Verhalten der Benutzer, die Eigenschaften des Dienstes sowie Cachezeit und Cache-Update-Strategien sorgfältig betrachtet werden.