Webcrawling mit Playwright in Golang
Es gibt verschiedene Methoden, um Daten zu sammeln, aber die gebräuchlichste Methode ist die Verwendung der Technik des Web-Crawlings.
Das Wort “Crawling” kann als “Kriechen” übersetzt werden. Web-Crawling bedeutet, durch das Web zu kriechen und Informationen zu sammeln.
Werkzeuge
Python wird besonders häufig verwendet, teilweise wegen der Einfachheit der Programmiersprache, aber auch wegen der Vielzahl an spezialisierten Bibliotheken für das Crawling. Bekannte Werkzeuge sind BeautifulSoup, Selenium und Scrapy.
Kürzlich wurde ein neues Tool namens Playwright veröffentlicht, das zwar hauptsächlich für die Testautomatisierung verwendet wird, aber auch für das Crawling genutzt werden kann. Anders als BeautifulSoup, das lediglich als Parser fungiert, kann Playwright browserbezogene Aktionen basierend auf einem echten Browser steuern, was nützlich ist, um JavaScript auszuführen oder für das Crawling von SPA(Single Page Applications).
Dieses Tool unterstützt verschiedene Programmiersprachen, darunter Node.js, Python und Go. In diesem Beitrag werde ich Playwright mit Go verwenden.
Installation von Playwright
Um Playwright in Go zu nutzen, müssen wir zunächst mit Hilfe der Bibliothek playwright-go installieren.
Du kannst es mit dem folgenden Befehl installieren.
go get github.com/playwright-community/playwright-goAußerdem musst du die Abhängigkeiten für den Browser installieren, der vom Crawler ausgeführt wird. Dies kann einfach mit dem folgenden Befehl geschehen.
go run github.com/playwright-community/playwright-go/cmd/playwright@latest install --with-depsImplementierung von Crawling mit Playwright
Nun lass uns tatsächlich ein Beispiel für Webcrawling ausprobieren.
Ich werde einfach den aktuellen Blog crawlen.
Da der Code etwas länger ist, werde ich ihn in Schritten erklären.
1. Einrichtung von Playwright
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
defer pw.Stop()
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Headless: playwright.Bool(true), // Wenn es auf false gesetzt ist, wird der Browser angezeigt
})
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
defer browser.Close()
page, err := browser.NewPage(playwright.BrowserNewPageOptions{
UserAgent: playwright.String("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"),
})
if err != nil {
log.Fatalf("could not create page: %v", err)
}
defer page.Close()Zuerst erzeugt die Funktion playwright.Run() eine Playwright-Instanz. Diese Instanz wird verwendet, um den Browser auszuführen und Seiten zu erstellen.
Die Funktion playwright.BrowserType.Launch() startet den Browser. Diese Funktion nimmt die Struktur playwright.BrowserTypeLaunchOptions als Parameter, wobei die Headless-Option, wenn sie auf true gesetzt ist, den Browser unsichtbar ausführt.
Es gibt viele andere Optionen, die du spezifizieren kannst. Weitere Informationen findest du in der offiziellen Dokumentation. Da die Erklärungen auf JavaScript basieren, musst du jedoch die Kommentare im Code selbst nachsehen, um sie in Go zu verwenden.
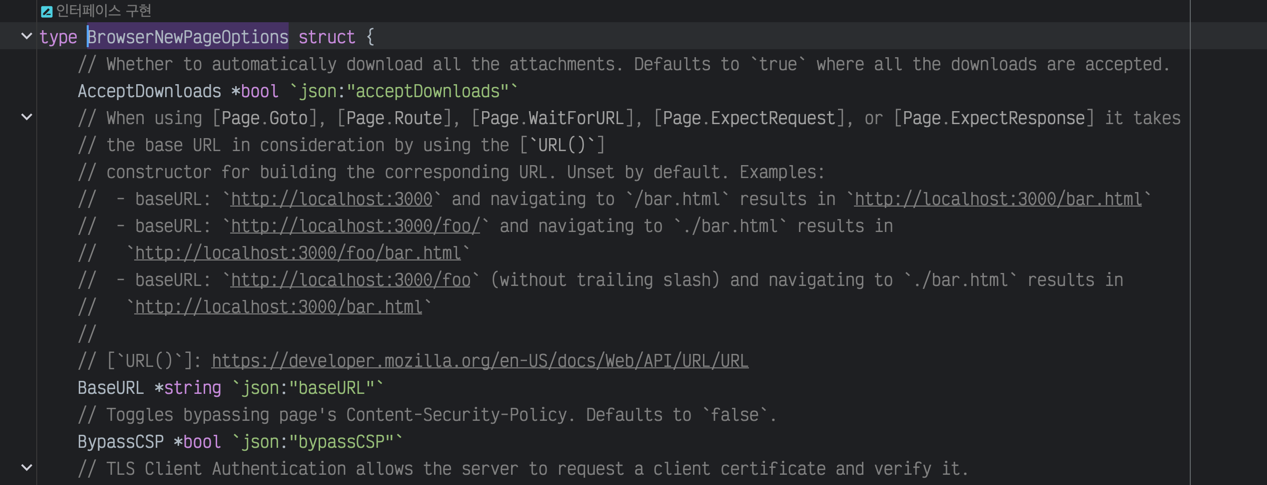
Browser-Options-Kommentare anzeigen
Die Funktion browser.NewPage() erstellt eine neue Seite. Sie nimmt die Struktur playwright.BrowserNewPageOptions als Parameter, wobei die UserAgent-Option den User-Agent des Browsers spezifiziert.
Üblicherweise überprüfen viele Websites den User-Agent. Dies ist besonders dann relevant, wenn Bots blockiert werden sollen oder um die Ausführung bestimmter JavaScript-Codes zu verhindern.
Ich habe Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3 als User-Agent gesetzt, um es so aussehen zu lassen, als käme der Zugriff von einem echten Browser.
2. Crawling
Lass uns jetzt anfangen zu crawlen.
Da die folgenden Funktionen wahrscheinlich oft verwendet werden, werde ich ihre Anwendung nacheinander erläutern.
Goto: Wechseln zu einer Seite über die URL
response, err := page.Goto("https://yangtaeyoung.github.io/blog", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateLoad,
})
if err != nil {
log.Fatalf("could not goto: %v", err)
}Goto ist eine Funktion, die von der Seite abgeleitet ist und zur angegebenen URL navigiert. Die Funktion nimmt die Struktur playwright.PageGotoOptions als Parameter, wobei die WaitUntil-Option das Warten auf das Laden der Seite spezifiziert.
Abhängig von der Option können dies playwright.WaitUntilStateLoad, playwright.WaitUntilStateNetworkidle oder playwright.WaitUntilStateDomcontentLoaded sein. Ich habe oft playwright.WaitUntilStateNetworkidle verwendet, was bedeutet, dass der Crawler wartet, bis keine Netzwerkaktivitäten mehr stattfinden.
In der Beispielverwendung wird playwright.WaitUntilStateLoad verwendet, da es sich bei meinem Blog um eine statische Seite handelt, bei der kein JavaScript speziell geladen werden muss.
Locator: Finden von Elementen
Nun zur wesentlichen Komponente des Crawlings: das Finden von Elementen. In Playwright kannst du die Funktion Locator verwenden, um Elemente auf verschiedene Arten zu finden.
Betrachten wir zunächst die Kategorieseite meines Blogs. Das Ziel ist es, alle Kategorietitel mit Sternsymbolen zu extrahieren.
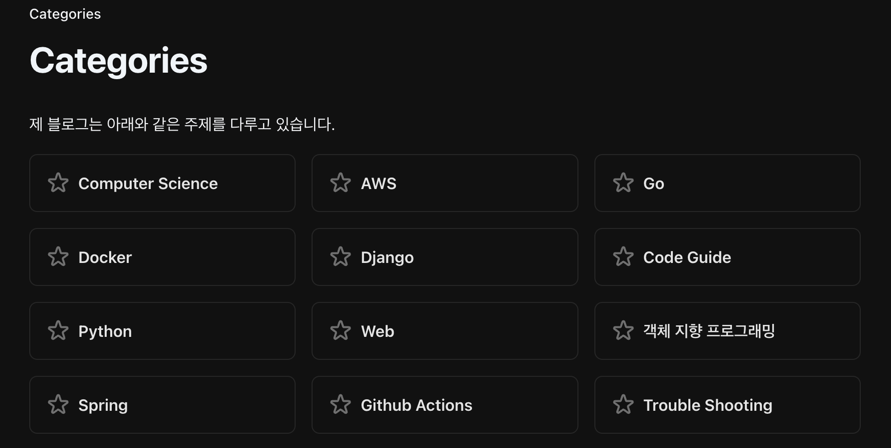
Wähle zunächst das gewünschte Element aus, klicke mit der rechten Maustaste darauf und wähle “Untersuchen”.
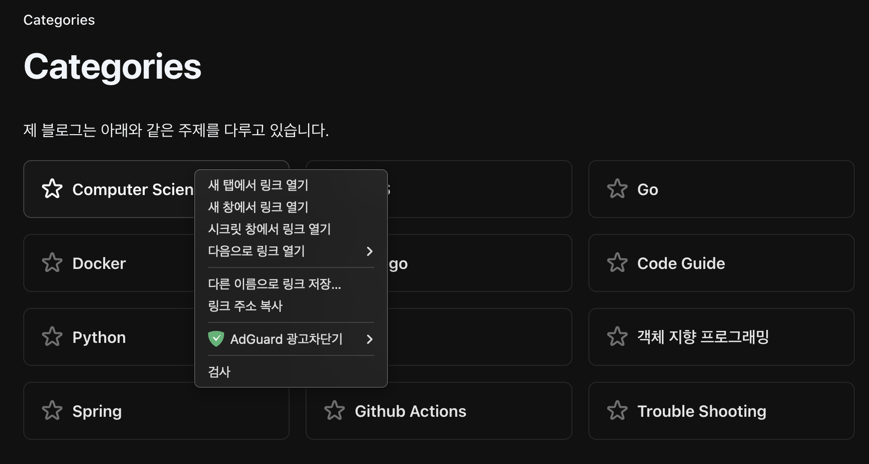
Nun erscheint der Quellcode, und wir müssen feststellen, welche Gesetzmäßigkeiten für die einzelnen Kategorien bestehen.
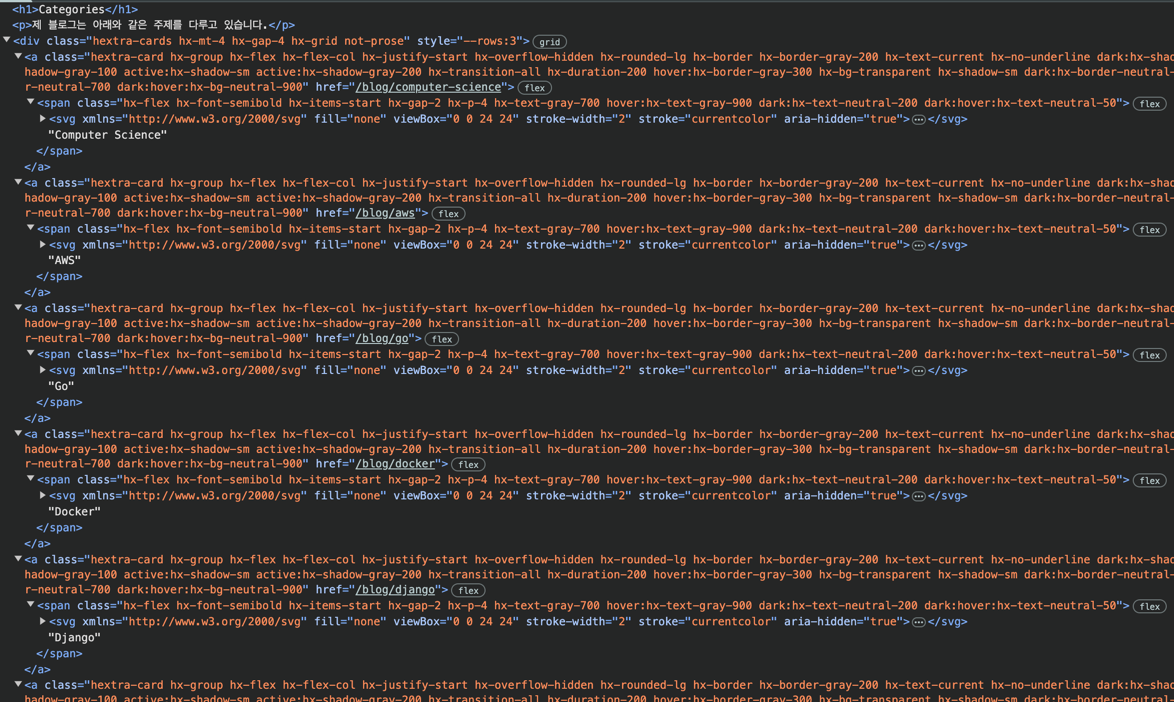
Alle Titel befinden sich in span-Tags unterhalb von a-Tags, die wiederum unterhalb von div-Tags liegen.
Allerdings gibt es viele solcher Fälle, daher müssen wir spezifischere Gesetzmäßigkeiten herausfinden.
Beim Betrachten der Klassen erkennen wir, dass div-Tags die Klasse hextra-cards und a-Tags die Klasse hextra-card haben.
Da sich keine anderen Gesetzmäßigkeiten erkennen lassen, müssen wir die folgenden auswählen:
`div-Tag mit der Klasse hextra-cards, darunter a-Tag mit der Klasse hextra-card, darunter span-Tag`Lass uns das in Code übersetzen:
titleElements, err := page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span").All()
if err != nil {
log.Fatalf("could not find elements: %v", err)
}
}Wie page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span") bereits zeigt, können Locator-Funktionen chained werden. Das bedeutet, dass wir zuerst div.hextra-cards finden, dann a.hextra-card darunter und schließlich span.
Ein einziger Locator kann ebenfalls verwendet werden, aber ich wollte die gesamten Kategorien erhalten, daher habe ich mit All() alle übereinstimmenden Locator gesammelt und in titleElements gespeichert.
Nun lassen wir uns die Titel extrahieren. Dabei gibt es jedoch ein Problem.

Da ist ein winziges svg-Tag für das Sternsymbol eingebaut.
Ein reines Ziehen des InnerHTML führt dazu, dass auch das svg-Tag zurückgegeben wird. Wenn wir nur die Titel wünschen, müssten wir die Tags zusätzlich entfernen.
Glücklicherweise gibt es in Playwright die Funktion InnerText(), die nur den internen Text zurückgibt. Diese können wir verwenden, um nur die title zu extrahieren, wie folgt:
titles := make([]string, len(titleElements))
for _, titleElement := range titleElements {
var title string
title, err = titleElement.InnerText()
if err != nil {
log.Fatalf("could not get inner text: %v", err)
}
titles = append(titles, title)
}
slog.Info("Success Crawled Titles", "titles", titles)Auf diese Weise erhalten wir den folgenden Code:
2025/02/14 02:00:13 INFO Success Crawled Titles titles="[ Computer Science AWS Go Docker Django Code Guide Python Web objektorientierte Programmierung Spring Github Actions Fehlerbehebung]"Die Kategorietitel wurden erfolgreich gecrawlt.
Es gibt noch weitere nützliche Funktionen, die häufig verwendet werden:
| Funktionsname | Beschreibung |
|---|---|
GetAttribute() | Holt ein Attribut des Elements. Zum Beispiel, um den Wert des href-Attributs in einem A-Tag zu erfahren. |
Click() | Klickt auf ein Element. Wenn der JavaScript basierte Klick-Link nicht direkt ermittelt werden kann, kann damit der Crawler den Klick anstoßen. |
InnerHTML() | Gibt den internen HTML-Code eines Elements zurück. |
IsVisible() | Überprüft, ob ein Element sichtbar ist. Gibt false zurück, wenn das Element nicht vorhanden ist oder die display-Eigenschaft auf none gesetzt ist. |
IsEnabled() | Überprüft, ob ein Element aktiviert ist. |
Count() | Gibt die Anzahl der Elemente zurück. |
Da ich meistens einfaches Crawling betreibe, verwende ich häufig InnerText, InnerHTML und GetAttribute. Es gibt jedoch viele weitere Funktionen, und auch wenn man sich den Code nur kurz ansieht, wird vieles intuitiv und durch die hilfreichen Erklärungen und Namen gut verständlich.
Heutzutage erklärt es auch GPT sehr gut.
Bild der Funktionsliste bei der Autovervollständigung, mit einer Vielzahl an Funktionen
Gesamter Code
Ich teile den gesamten Code, den ich geschrieben hatte, um die Kategorien zu extrahieren. Ich hoffe, durch das viele Ausführen des Codes steigen die Besucherzahlen meines Blogs signifikant. 🤣
package main
import (
"log"
"log/slog"
"github.com/playwright-community/playwright-go"
)
func main() {
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
defer pw.Stop()
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Headless: playwright.Bool(true), // Wenn es auf false gesetzt ist, wird der Browser angezeigt
})
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
defer browser.Close()
page, err := browser.NewPage(playwright.BrowserNewPageOptions{
UserAgent: playwright.String("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"),
BypassCSP: playwright.Bool(true),
})
if err != nil {
log.Fatalf("could not create page: %v", err)
}
defer page.Close()
if _, err := page.Goto("https://yangtaeyoung.github.io/blog", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateNetworkidle,
}); err != nil {
log.Fatalf("could not goto: %v", err)
}
titleElements, err := page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span").All()
if err != nil {
log.Fatalf("could not find title elements: %v", err)
}
titles := make([]string, len(titleElements))
for _, titleElement := range titleElements {
var title string
title, err = titleElement.InnerText()
if err != nil {
log.Fatalf("could not get inner text: %v", err)
}
titleElement.
titles = append(titles, title)
}
slog.Info("Success Crawled Titles", "titles", titles)
}Fazit
Playwright scheint hauptsächlich in der Testautomatisierung verwendet zu werden, wird aber in der Golang-Community nicht so häufig eingesetzt. (Besonders in Korea scheinen entsprechende Materialien spärlich vorhanden zu sein)
Das Crawling mit Go ist inzwischen recht flexibel und in den frühen Phasen eines Projekts kann die Datenerhebung schwierig sein. Solche Tools können beim Sammeln von Daten für Big-Data-Analysen oder KI sehr hilfreich sein.