API 서버 관점에서 이벤트 기반 아키텍처(Event Driven Architecture)를 알아보자
간혹 개발을 하다 보면, API 응답이 느릴 때가 있다. 이런 경우, API의 응답을 빠르게 하기 위해 코드를 최적화하거나, 캐시를 적용하는 등의 방법을 사용할 수 있다.
물론 이런 방법들은 된다면 좋은 방법이고, 최선이겠지만, 때로는 어쩔 수 없이 시간이 많이 걸리는 작업들이 있다.
AWS로 예를 들어보자, 특정 API가 있고, EC2 머신을 하나 띄우는 API가 있다고 가정한다. 이 때, EC2 머신을 띄우는 API는 시간이 꽤 걸리는 작업이다. 근데 코드 최적화 만으로 이 시간을 단축할 수 있을까?
컴퓨터를 켜고, 끄는 작업은 아무리 최적화를 한다 해도, 시간이 꽤 오래 걸릴 것이다. (필자의 컴퓨터도 부팅하는데 30초는 족히 걸릴 것이다)
이를 동기 API로 처리한다면, 다음과 같이 구성할 수 있을 것이다.
Go 언어를 통해 한번 살펴보자
package main
import "net/http"
func StartEc2Handler(w http.ResponseWriter, r *http.Request) {
// ...
// EC2 머신을 띄우는 코드
// ...
w.Write([]byte(`{"result": "success"}`)) // JSON 형태로 응답
}단순히 계층간 구분 없이 코드를 작성하였다. 실제 코드에서는 service, repository 등 다양한 계층이 있을 것이다.
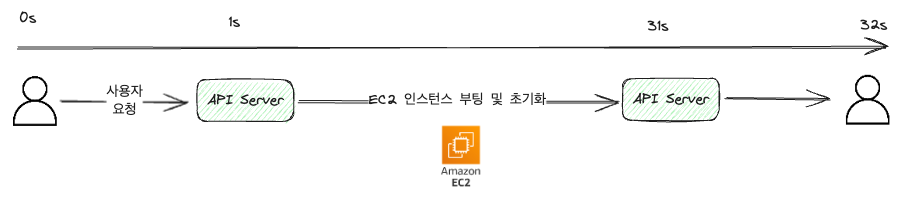
위 그림에서의 예는 편의를 위해 극단적으로 유저 -> 서버 간 통신에 1초가 걸린다고 가정하였다.(실제는 ms 단위로 훨씬 짧을 것이다.)
그림에서 볼 수 있듯 API 요청을 받아서 EC2 머신을 띄우는 작업을 처리하고, 그 결과를 반환하는 방식이다.
동기 방식은 요청을 받으면 해당 요청을, 처리할 때까지 응답하지 않기 때문에 페이지를 벗어나거나, 새로고침 등의 작업을 하면 작업이 도중에 중단된다.
사용자 입장에서는 다음과 같은 로딩화면을 32초간 보아야 하는 것이다.
가히 끔찍한 일이 아닐 수 없을 것이다.
중간에 끊기는 걸 방지하기 위해 다음과 같이 경고가 나오게 처리하는 경우도 있다. 근데 사용자가 확인을 누르는 것은 막을 수 없다.
필자의 경우 B2B 서비스에서 상품 1개를 3개의 외부 서비스에 업로드 하는데 걸리는 시간이 개당 10초 남짓이었고, 일반적으로 100~200개 단위로 업로드하기에, 사용자가 10분 이상 기다리는 것은 매우 불편한 일이었다.
컴퓨터 10분간 하지 마세요.-> 참을 수 있는가?
해결1. API를 비동기로 만들기
이벤트 기반으로 처리하기 전에, 비동기 API로 작업을 처리할 수 있다.
Go가 동시성 처리가 쉬운 편이라 Go를 예로 들어 하자면 다음과 같은 식이다.
package main
import "net/http"
func StartEc2Handler(w http.ResponseWriter, r *http.Request) {
// ...
go func() {
// EC2 머신을 띄우는 코드
// 성공/실패에 대한 유저 알림을 생성하는 코드
}()
// ...
w.WriteHeader(http.StatusAccepted) // 202 Accepted: 요청이 수신되었으며, 작업이 시작되었음을 나타냄
}위 코드는 EC2 머신을 띄우는 코드를 고루틴으로 처리하고, 요청이 수신되었으며, 작업이 시작되었음을 나타내기 위해 202 Accepted를 반환하는 코드이다.
이렇게만 하더라도 다음과 같이 요청 -> 응답에서 이어지는 시간을 크게 단축할 수 있다.
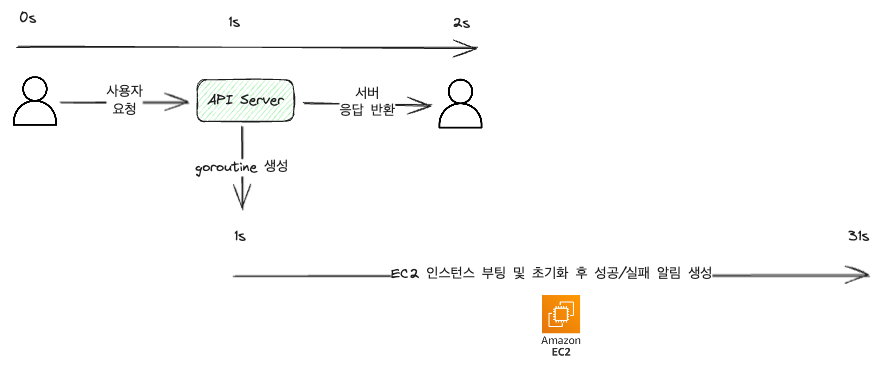
위만 봐도 사용자의 요청은 2초정도만 잡고 있고, 매우 빠르게 응답을 받을 수 있다. 다만 알림을 생성하는 코드가 추가 되었다.
왜냐하면 202는 단순히 수신되었다는 것을 알리는 것일 뿐 실제 작업이 완료되었는지는 보장하지 않기 때문이다.
따라서 이렇게 성공/실패와 관계 없이 응답을 하는 경우에는 알림이나, 상태 코드등을 보도록 추가해서 클라이언트에게 작업의 성공/실패 여부를 알릴 수 있도록 해야 한다.
물론 알림 처리는 하지 않아도 코드적으로는 상관은 없다. 다만 개발자라면 사용자가 알림 등을 통해 작업의 성공/실패 여부를 알 수 없다는 것이 사용자 경험을 크게 해치며, 빠른 시일 내에 알림을 추가하는 것을 고려해야 한다.
해치웠…나?
그렇진 않다. 세상엔 여러가지 제약사항이 있고, 여러가지 문제가 있다.
다음과 같은 코드를 늘리다 보면 여러가지 문제에 대해 직면하게 되는데 필자가 맞이하였던 문제는 다음 3개 였다
- 일반적으로 비동기 작업은 성능 부하가 큰 작업이다 (그렇지 않다면 동기로 처리하는 것이 간단하기도 하고 문제가 없었을 것이다). 그렇기 때문에 해당 API로의 트래픽이 많아지면 쉽게 서버가 다운될 수 있다.
- 배포, 천재지변 등의 이유로 작업이 중단되는 경우, 복구가 어려우며, 사용자에게는 알림이 가지 않는다.
- 자사 서비스가 아닌 외부 서비스 API인 경우 일반적으로 Rate Limit이 존재하며, 요청이 몰리는 경우, 429 Too Many Requests를 외부 서비스에서 제대로 작업이 처리되지 않을 수 있다.
해결 2. 이벤트 기반 아키텍처(Event Driven Architecture)로 처리하기
이벤트 기반 아키텍처는 말 그대로 이벤트를 기반으로 작업을 처리하는 아키텍처를 의미한다.
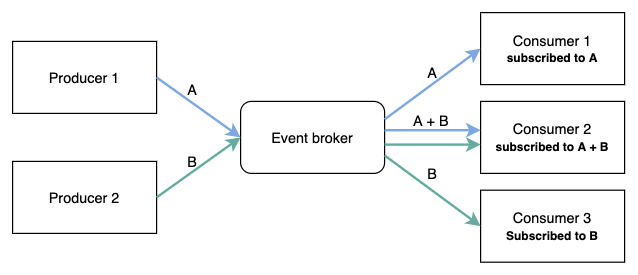
중간에 Event Broker가 존재하며, Producer가 이벤트를 발행하고, Consumer가 이벤트를 구독하는 방식으로 작업을 처리한다.
Event Broker는 대표적으로 Kafka, RabbitMQ, AWS SNS 등이 있으며, Producer와 Consumer는 이를 통해 이벤트를 주고 받는다.
실질적으로 작업(EC2머신을 띄우는 등)을 처리하는 것은 Consumer가 담당하며, Producer는 요청을 받으면 이벤트를 발행하고, 해당 API는 202 Accepted를 반환한다.
코드로 한번 살펴보자
아래 예시에서는 RabbitMQ를 사용하여 이벤트를 발행하고, 이를 구독하는 방식으로 작업을 처리한다.
package main
import (
"net/http"
amqp "github.com/rabbitmq/amqp091-go"
)
func PublishStartEc2EventHandler(w http.ResponseWriter, r *http.Request) {
// rabbitmq 연결 및 channel 가져오기
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
w.Write([]byte(`{"result": "rabbitmq connection error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
ch, err := conn.Channel()
if err != nil {
w.Write([]byte(`{"result": "rabbitmq channel error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
// 이벤트 발행
event, err := json.Marshal(Event{
Code: "START_EC2",
RequestID: "some_uuid",
Body: "some_body",
})
if err != nil {
w.Write([]byte(`{"result": "json marshal error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
if err = ch.PublishWithContext(
r.Context(),
"",
"aws-event-queue",
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: event,
}); err != nil {
w.Write([]byte(`{"result": "rabbitmq publish error"}`))
w.WriteHeader(http.StatusInternalServerError)
return
}
w.WriteHeader(http.StatusAccepted)
}코드가 조금 길다. 사실 코드가 중요한 건 아니고, 해당 API의 역할이 중요하다고 볼 수 있다.
해당 API에서는 RabbitMQ 연결 -> 이벤트 객체 생성 -> JSON 직렬화 -> 이벤트 객체를 Body에 넣고 이벤트 발행 순서로 작업을 처리한다.
사실 Queue와의 연결 자체도 일반적으로는 어플리케이션 구동 시 커넥션을 공유해서 사용하기에 필요하진 않은 경우가 대다수이나, 해당 경우에는 난데 없이
conn.Channel()이 나오면 이게 뭔가 싶을 것 같아, 이해를 돕기 위해 코드에 포함하였다.
Consumer 코드는 기능에 따라 매우 길기 때문에 다음 그림으로 생략한다
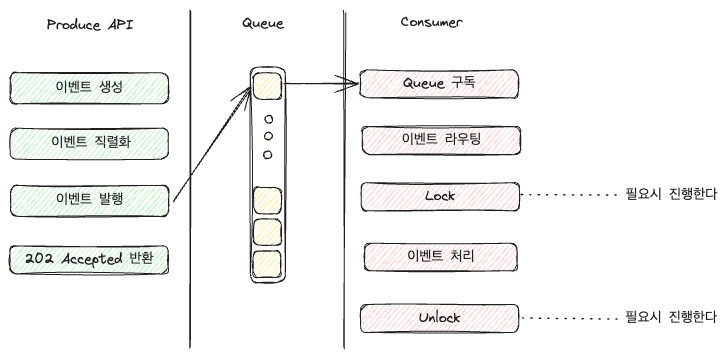
라우팅의 경우 구성에 따라 각각의 이벤트만을 위한 Queue를 만들어 Queue에서 직접 처리하게 할 수도 있고, 위 그림처럼 Application에서 이벤트를 받아 라우팅 할 수 있다.
다만 위 그림처럼 Consumer의 역할이 늘어나며, 이벤트가 많아질 수록 분기에 대한 부담이 커질 수 있다.
크기가 좀 더 커지면 (정확히는 관리가 어려워지면), 이벤트 분기를 처리하는 별도의 레이어를 둔다던가, Consumer를 지정하는 LB 같은 걸 둘 수도 있을 것 같다.
락을 왜 잡나?
이벤트 기반 아키텍처에서는 Consume 시 선택적으로 락을 잡을 수 있다.
Lock은 RedisLock, DB Lock 등 특정 자원에 대한 동시성을 제어하기 위한 방법이다.
락은 일반적으로 걸고 있으면 다른 Consumer에서 특정 이벤트, 혹은 특정 큐를 처리하지 못하게 막을 수 있다. 그리고 작업이 끝나면 락을 해제하여, 다른 Consumer가 해당 이벤트를 처리할 수 있게 한다.
필자의 경우 다음과 같은 이유로 주로 락을 잡았는데
- 멀티 컨테이너 환경에서는 필연적으로 Consumer가 복수개가 존재한다. 락을 별도로 잡지 않는 경우 다른 컨테이너가 해당 큐에서 작업을 수행하고 있음을 알 수 없을 수 있기 때문에, 컨테이너 수만큼 동시에 소모하는 경우가 생길 수 있다. 필자의 경우 이처럼 한번에 처리되는 이벤트의 양을 제한하기 위해 락을 잡았다.
- Consumer가 여러 개일 경우, 동일한 이벤트를 처리하는 경우가 있을 수 있기 때문에, 이를 방지하기 위해 락을 잡았다.
- 외부 서비스의 경우 대부분 부하를 막기 위해 한번에 처리할 수 있는 요청 수가 정해져 있다. 필자의 경우 Rate Limit이 1초에 2개 정도로 매우 제한적이었기 때문에, 한번에 처리되는 외부 서비스 API가 하나임을 보장하기 위해 락을 잡았다.
Event Chain
이벤트 기반 아키텍처의 장점은 이벤트 체인을 통해 여러 이벤트를 연결하도록 만들 수도 있다는 것이다.
예를 들어 EC2 핸들러의 경우 2개의 작업이 있었다
- EC2 머신을 띄우는 작업
- 띄운 EC2 머신에 대한 알림을 생성하는 작업
이를 이벤트 체인으로 만들면 다음과 같다.
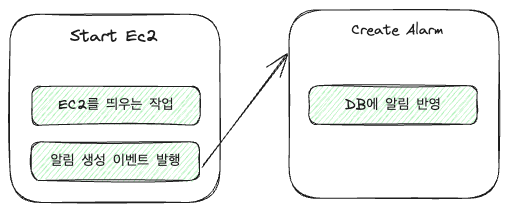
코드로 보면 더 쉬운데 매우 단순하게 구성하면 다음과 같다
func StartEc2Event(args any) {
// EC2 머신을 띄우는 작업
// ... Some code
// CreateAlarm 이벤트 발행
ch.PublishWithContext(
r.Context(),
"",
"aws-event-queue",
false,
false,
amqp.Publishing{
ContentType: "application/json",
Body: event, // 대충 해당 작업이 성공했다는 내용
})
}
func CreateAlarm(args any) {
// 알림 생성
}Comsumer의 함수이지만, StartEc2Event함수를 보면 이벤트를 소모하고 새롭게 이벤트를 발행한다. 이렇게 되면, 순서가 있는 다음 작업을 이벤트 기반으로 쉽게 구현할 수 있다.
이벤트가 표준화가 잘 되어있을수록, 재사용 성이 높아진다. 예시에 제시딘 CreateAlarm의 경우, 단순히 해당 케이스 뿐만 아니라, 이런 비동기 작업들이라면 어떤 이벤트들에서도 그대로 사용할 수 있을 것이다.
생상성 면에서는 이미 구현한 이벤트를 다시 구현할 필요가 없다는 점에서 매우 큰 장점으로 다가올 수 있다.
단점
이렇게 그럼으로 보면 굉장히 쉬워보이지만, 코드로 보면 상황에 따라서는 매우 복잡할 수 있다.
이벤트 체인이 깊어지면 깊어질 수록, 해당 흐름을 쫒아가기 굉장히 어려우며, 디버깅 시에도 각 이벤트 간의 관계를 파악하기 어려울 수 있다.
그렇기에 이벤트들은 그들과의 관계를 매우 잘 문서화 해두어야 한다.
마치며
이벤트 기반 아키텍처는 잘 사용하면 매우 강력한 아키텍처 중 하나이다. Consume 되는 API의 수를 조정해, 서버의 부하를 줄일 수 있고, 이벤트 체인을 통해 재사용성을 높일 수 있다.
사용자 입장에서도, 요청 -> 응답에 대한 대기시간을 줄이면서도 다른 작업을 할 수 있게 해주는 고마운 기술이다. 다만 모니터링과 같은 부분에서도 한 트랜잭션으로 묶기 위해 별도의 설정을 해주어야 하며, 이벤트 객체를 잘못 만들어서, 단순히 동기 API로 처리 할 때보다 훨씬 복잡도가 높아질 수도 있다.
그렇기에 필자는 이벤트 기반 아키텍처를 사용할 때에는 팀원들과 충분한 논의와 컨벤션을 미리 정립하고, 이를 잘 지켜나가고 보존시키는 것이 중요하다고 생각한다.