Golang에서 Playwright를 이용해 크롤링을 해보자
데이터를 수집하는 방법에는 여러가지가 있는데, 가장 흔한 방식이 크롤링(Crawling)이라는 기법을 이용하는 것이다.
크롤링이란 직역하면 기어다니다 라는 뜻이다. 웹 크롤링은 웹을 기어다니면서 정보를 수집하는 것이라고 생각하면 된다.
도구
파이썬에서 특히 많이 사용하는데, 이유로는 파이썬 언어의 간결함도 있지만, 크롤링에 특화된 라이브러리가 많기 때문이다. 많이 알려진 도구로는 BeautifulSoup, Selenium, Scrapy 등이 있다.
최근에는 Playwright라는 도구가 나와있는데, 일반적으로는 크롤링보단 테스트 자동화에 많이 사용되지만, 크롤링에도 사용할 수 있다. 단순히 파서 역할만 하는 BeautifulSoup와는 달리, Playwright는 실제 브라우저를 기반으로 브라우저 관련 액션들을 제어할 수 있어서, JavaScript를 실행하거나, SPA(Single Page Application)를 크롤링할 때에도 유용하게 사용할 수 있다.
해당 도구는 Node.js, Python, Go 등 다양한 언어를 지원하는데, 이번에는 Go로 Playwright를 사용해보려고 한다.
Playwright 설치
Playwright를 Go에서 사용하기 위해서는 먼저 playwright-go 라는 라이브러리를 이용하여야 한다.
아래의 명령어를 이용해 설치할 수 있다.
go get github.com/playwright-community/playwright-go또한 크롤러를 실행할 브라우저 의존성을 설치해야 한다. 아래의 명령어를 이용하여 쉽게 설치할 수 있다.
go run github.com/playwright-community/playwright-go/cmd/playwright@latest install --with-depsPlaywright를 이용한 크롤링 구현하기
이제 실제로 크롤링을 해보자
간단하게 현재의 블로그를 크롤링해보겠다.
코드가 길기에 순서대로 설명한다.
1. Playwright 셋업
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
defer pw.Stop()
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Headless: playwright.Bool(true), // false 인 경우 브라우저가 보임
})
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
defer browser.Close()
page, err := browser.NewPage(playwright.BrowserNewPageOptions{
UserAgent: playwright.String("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"),
})
if err != nil {
log.Fatalf("could not create page: %v", err)
}
defer page.Close()먼저 playwright.Run() 함수는 playwright 인스턴스를 생성한다. 이 인스턴스는 브라우저를 실행하고 페이지를 생성하는데 사용된다.
playwright.BrowserType.Launch() 함수는 브라우저를 실행한다. playwright.BrowserType.Launch() 함수는
playwright.BrowserTypeLaunchOptions 구조체를 인자로 받는데, 여기서 Headless 옵션을 true로 설정하면 브라우저가 보이지 않게 실행된다.
그 외에도 다양한 옵션을 지정할 수 있는데, 자세한 내용은 공식 문서를 참고하자. 다만 설명이 JavaScript 기준이라서 Go에서 사용할 때는 함수를 직접 들어가서 주석을 보는 등의 방법을 사용해야 한다.
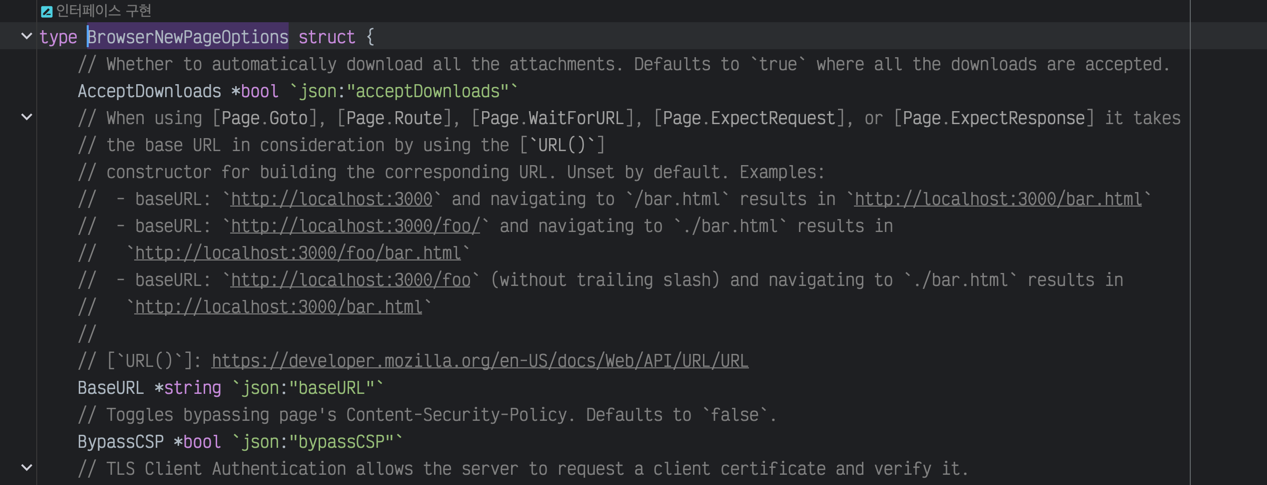
브러우저 옵션 주석 참조
browser.NewPage() 함수는 새로운 페이지를 생성한다. playwright.BrowserNewPageOptions 구조체를 인자로 받는데, 여기서 UserAgent 옵션은 브라우저의
UserAgent를 설정한다.
일반적으로 많은 사이트들에서 UserAgent를 확인한다. 특히 봇 같은걸 차단하거나, 일부 JavaScript를 실행하지 않도록 막는 경우가 이에 해당한다.
필자가 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3
과 같이 UserAgent를 설정한 이유는 마치 실제 브라우저에서 접속하는 것처럼 보이기 위함이다.
2. 크롤링
자 이제 크롤링을 해보자
가장 많이 하게될 함수들이 나올 예정이므로, 하나하나 끊어서 사용하는 방법을 설명하겠다.
Goto: URL기반 페이지 이동하기
response, err := page.Goto("https://yangtaeyoung.github.io/blog", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateLoad,
})
if err != nil {
log.Fatalf("could not goto: %v", err)
}Goto의 경우 page에서 파생된 함수로, 해당 페이지로 이동한다. playwright.PageGotoOptions 구조체를 인자로 받는데, 여기서 WaitUntil 옵션은 페이지가 로드될 때까지 기다리는
옵션이다.
옵션에 따라 playwright.WaitUntilStateLoad, playwright.WaitUntilStateNetworkidle,
playwright.WaitUntilStateDomcontentLoaded 등이 있다.
여기서 필자는 playwright.WaitUntilStateNetworkidle을 자주 사용했는데, 이 옵션은 네트워크가 더 이상 요청을 하지 않을 때까지 기다리는 옵션이다.
필자의 경우 클라이언트 사이드 렌더링을 하는 페이지의 경우 단순히 Load만 하는 경우 실제 내용이 완전히 로드되지 않는 경우가 있어서 사용했다.
예시에서는 playwright.WaitUntilStateLoad를 사용하는데 내 블로그는 정적 페이지이기 때문에 따로 자바스크립트를 기다리지 않아도 되기 때문이다.
Locator: 요소 찾기
이제 크롤링의 꽃이라 볼 수 있는 요소 찾기이다. Playwright에서는 Locator함수를 이용하여 다양한 방식으로 요소를 찾을 수 있다.
먼저 내 블로그의 카테고리 페이지이다. 별 모양이 들어간 카테고리 제목을 모두 가져오는 것을 목표로 해보자
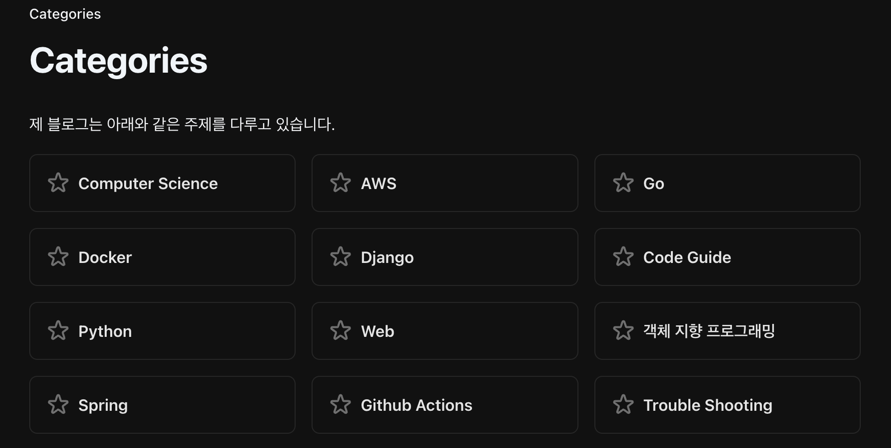
먼저 원하는 요소를 하나 찾아 우클릭 - 검사 버튼을 누른다
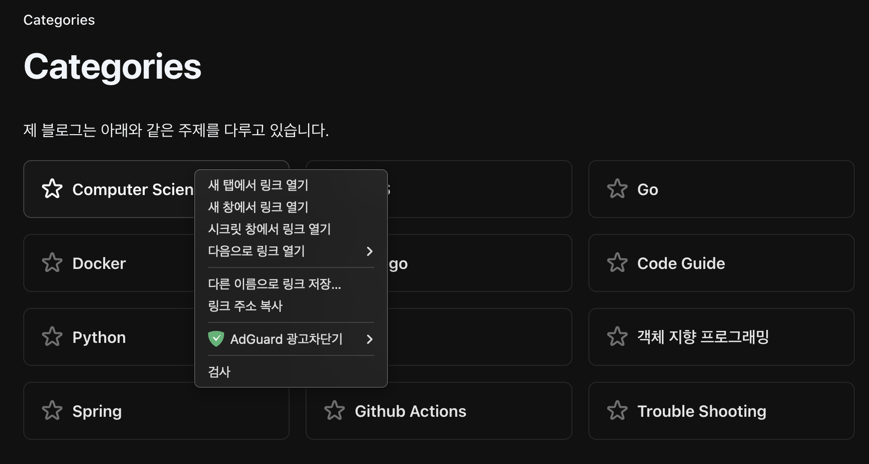
이제 소스코드가 나오고, 각 카테고리의 규칙성이 무엇인지 찾아보아야 한다.
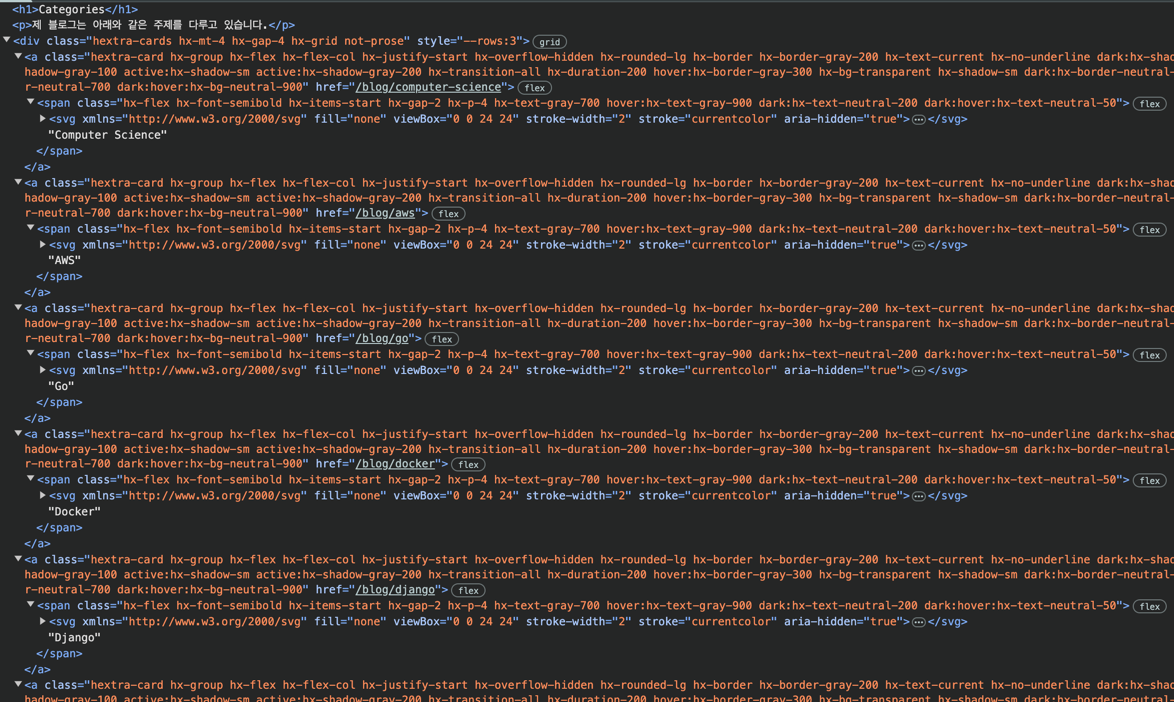
제목은 모두 div태그 아래 a태그 아래 span태그에 들어가 있다.
다만 잠깐만 생각해도, 그런 경우는 매우 많을 것이므로, 좀 더 구체적인 규칙성을 찾아야 한다.
클래스를 보자, div태그에는 hextra-cards가 a태그에는 hextra-card가 있다.
이외의 다른 요소를 보았을 때는 다른 규칙성은 보이지 않는다.
그럼 찾아야 하는 것은 다음과 같다
`hextra-cards 클래스를 가진 div 태그 아래 hextra-card 클래스를 가진 a 태그 아래 span 태그`이제 이를 코드로 옮겨보자
titleElements, err := page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span").All()
if err != nil {
log.Fatalf("could not find elements: %v", err)
}
}page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span")처럼 Locator는 체이닝이 가능하다. 이는 div.hextra-cards를
찾고, 그 아래 a.hextra-card를 찾고, 그 아래 span을 찾는다는 의미이다.
단일 Locator를 사용할 수도 있지만, 필자는 카테고리 전체를 가져오고 싶으므로, All()을 이용해 매칭된 모든 Locator들을 가져와서 titleElements에 저장했다.
이제 제목을 뽑아보자 제목을 보니 문제가 있다.

위처럼 별을 표현하기 위해 조막만한 svg태그가 들어가 있다.
단순히 InnerHTML을 사용하면 svg태그까지 같이 나오게 된다. 이는 제목만 뽑기 위해 태그를 제거해야 하는 등의 노력이 추가로 필요하다.
이런 경우가 많았는지 다행이도 playwright에서는 내부 텍스트만 가져오는 InnerText() 함수를 제공한다. 이를 이용해 title만 뽑아보면 다음과 같다
titles := make([]string, len(titleElements))
for _, titleElement := range titleElements {
var title string
title, err = titleElement.InnerText()
if err != nil {
log.Fatalf("could not get inner text: %v", err)
}
titles = append(titles, title)
}
slog.Info("Success Crawled Titles", "titles", titles)그럼 다음과 같은 코드를 얻어볼 수 있다.
2025/02/14 02:00:13 INFO Success Crawled Titles titles="[ Computer Science AWS Go Docker Django Code Guide Python Web 객체 지향 프로그래밍 Spring Github Actions Trouble Shooting]"멋지게도 카테고리 제목들이 잘 크롤링 되었다.
이외에도 잘 사용되는 함수들이 있고 다음과 같다.
| 함수명 | 설명 |
|---|---|
GetAttribute() | 요소의 속성을 가져온다. 예를 들어 A태그 내의 href 속성의 값을 알고 싶다면 해당 함수를 사용한다. |
Click() | 요소를 클릭한다. 특정 링크로 이동해야 하는데, 자바 스크립트로 되어 있어 링크를 알아낼 수 없다면, 크롤러에게 클릭을 지시할 수 있다. |
InnerHTML() | 요소의 내부 HTML을 가져온다. |
IsVisible() | 요소가 보이는지 확인한다. 요소가 아예 없거나, display 속성이 none이면 true를 반환한다. |
IsEnabled() | 요소가 활성화되어 있는지 확인한다. |
Count() | 요소의 개수를 반환한다. |
필자는 단순한 크롤링을 주로 해서 그런지, InnerText, InnerHTML, GetAttribute를 주로 사용했다. 이외에도 굉장히 다양한 함수들이 많이 있으나, 코드를 조금만 둘러보아도 알기 쉽게 설명이
되고 함수명도 익숙한 것들이 많아 사용하는 것이 그리 어렵지 않을 것이다.
요즘은 GPT가 잘 설명해주기도 한다.
자동완성으로 둘러보면 나오는 함수 리스트들 사진, 매우 다양한 함수들이 있다.
전체 코드
필자의 카테고리를 긁어오기 위해 작성했던 전체 코드를 공유한다. 해당 코드를 많이 돌려서 필자의 블로그 방문수가 급증하길 바라본다 🤣
package main
import (
"log"
"log/slog"
"github.com/playwright-community/playwright-go"
)
func main() {
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not start playwright: %v", err)
}
defer pw.Stop()
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Headless: playwright.Bool(true), // false 인 경우 브라우저가 보임
})
if err != nil {
log.Fatalf("could not launch browser: %v", err)
}
defer browser.Close()
page, err := browser.NewPage(playwright.BrowserNewPageOptions{
UserAgent: playwright.String("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"),
BypassCSP: playwright.Bool(true),
})
if err != nil {
log.Fatalf("could not create page: %v", err)
}
defer page.Close()
if _, err := page.Goto("https://yangtaeyoung.github.io/blog", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateNetworkidle,
}); err != nil {
log.Fatalf("could not goto: %v", err)
}
titleElements, err := page.Locator("div.hextra-cards").Locator("a.hextra-card").Locator("span").All()
if err != nil {
log.Fatalf("could not find title elements: %v", err)
}
titles := make([]string, len(titleElements))
for _, titleElement := range titleElements {
var title string
title, err = titleElement.InnerText()
if err != nil {
log.Fatalf("could not get inner text: %v", err)
}
titleElement.
titles = append(titles, title)
}
slog.Info("Success Crawled Titles", "titles", titles)
}마치며
Playwright는 테스트 자동화에서 많이 쓰이는 것 같던데, 아무래도 Golang 쪽은 많이 사용하진 않는 것 같다. (특히 한국에는 매우 이런 자료들이 부족한 것 같다는 생각이 들었다)
Go에서도 크롤링이 이제 굉장히 자유로워진 편이고, 프로젝트 초기에는 데이터 수집이 어려운데 이런 도구들을 활용하면 빅데이터 분석이나 AI에 필요한 데이터 수집도 쉽게 할 수 있을 것 같다.